UTF-8
Informatikan, UTF-8 (8 biteko Unicode Transformazio Formatua) testuetako karaktereak kodetzeko modu bat da. Munduan zehar erabiltzen diren alfabeto guztiak erabiltzeko aukera ematen du (latindar alfabetoa, grekoak, ziriliko, arabiarra...
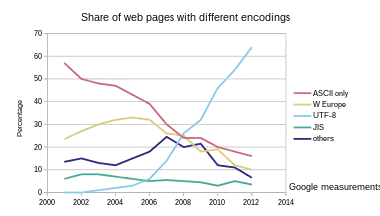
UNICODEko UTF-8 kodetze-modua erabiliena da gaur egunean. UTF-8 Weberako bereziki kodeketa ohikoena da, baita bigarrena baina askoz gehiago erabilia ere. 2020an Web orrialde guztien %95 baino gehiago dira UTF-8-rekin kodetuta daudenak. Are gehiago, % 100-ra arte ailegatu zen 2020an hizkuntza batzuetarako.
UTF-8 estandarra beti erabiltzeko aholkua
Landu behar dituen testu-fitxategi guztiak UTF-8 kodekeran jartzea komeni zaio Informatikariari. Horrela etorkizuneko hainbat arazo ekidingo du hasiera-hasieratik. Linux sistema eragileko iconv komandoa guztiz lagungarria da horretan; fitxategi berri bat jasotzen duen bakoitzean, informatikariak fitxategiaren kodetze-modua zein den jakin beharko du, eta UTF-8 ez bada, momentuan sortu beharko du fitxategiaren UTF-8 bertsioa (iconv komandoa erabiliz, esaterako).[2]
Adibidez, testukk.txt fitxategia ISO-8859-1 kodekeratik UTF-8 kodekera pasa eta emaitza testukk_utf8.txt fitxategian gorde:
$ iconv -f ISO-8859-1 -t UTF-8 -o testukk_utf8.txt testukk.txt
Zabalera aldakorreko errepresentazioa
Zabalera aldakorra erabiltzen du UTF-8k, kasu batzuetan karaktere bat errepresentatzeko byte bat (8 bit) erabiltzen du, eta beste kasu batzuetan byte gehiago, lau byte arteraino, eta horrela Unicodeko 1.112.064 kode desberdin[nb 1] (kode-puntu) definitzeko gai da. Kodetzeko modua Unicode estandarrak definitu zuen eta Ken Thompson-ek eta Rob Pike-k diseinatu zuten.[3] Izena sigla bat da, Unicode (edo Universal Coded Character Set ) Transformazio Format (8 bit) kontzeptutik eratorria da.

ASCIIrekin bateragarria izateko diseinatu zen. Zenbaki baxuenak dituzten kode-balioak (kode-puntuak) maizago gertatzen diren karaktereak errepresentatzeko erabiltzen dira; horrela byte gutxiagorekin kodetzen dira. Unicodeko lehen 128 karaktereak ASCIIkoak dira, ASCIIko balio bitar bera dute eta horiexek dira byte bakarra erabiltzen dutenak. Beraz, ASCIIz ondo kodetutako testu bat UTF-8-z ondo kodetutako testua ere bada. Baina testuan agertzen bada ASCII multzoan ez dagoen karaktererik, bat baino ez bada ere, esate baterako 'ñ' letra bat edo 'ü' letra bat, orduan arazoak sortuko dira fitxategi horren erabileran fitxategi osoa UTF-8rekin kodetu ez bada.[4]
| Byte kopurua | Kode-puntu bakoitzeko
bit kopurua |
Lehen kode-puntua | Azken kode-puntua | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | |||
| 2 | 11 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| 3 | 16 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 21 | U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Adibide batzuk:
| Character | Kodearen puntua | UTF-8 | ||||
|---|---|---|---|---|---|---|
| Zortzitarra | Bitarra | Bitarra | Zortzitarra | Hamaseitarra | ||
| $ | U+0024 | 044 | 010 0100 | 00100100 | 044 | 24 |
| ¢ | U+00A2 | 0242 | 000 1010 0010 | 11000010 10100010 | 302 242 | C2 A2 |
| ह | U+0939 | 004471 | 0000 1001 0011 1001 | 11100000 10100100 10111001 | 340 244 271 | E0 A4 B9 |
| € | U+20AC | 020254 | 0010 0000 1010 1100 | 11100010 10000010 10101100 | 342 202 254 | E2 82 AC |
| 한 | U+D55C | 152534 | 1101 0101 0101 1100 | 11101101 10010101 10011100 | 355 225 234 | ED 95 9C |
| 𐍈 | U+10348 | 0201510 | 0 0001 0000 0011 0100 1000 | 11110000 10010000 10001101 10001000 | 360 220 215 210 | F0 90 8D 88 |
Oharrak
- 17 planes times 216 code points per plane, minus 211 technically-invalid surrogates.
Erreferentziak
- (Ingelesez) «Unicode over 60 percent of the web» Official Google Blog (Noiz kontsultatua: 2020-06-12).
- «iconv(1) - Linux manual page» www.man7.org (Noiz kontsultatua: 2020-06-12).
- Email Subject: UTF-8 history, From: "Rob 'Commander' Pike", Date: Wed, 30 Apr 2003..., ...UTF-8 was designed, in front of my eyes, on a placemat in a New Jersey diner one night in September or so 1992...So that night Ken wrote packing and unpacking code and I started tearing into the C and graphics libraries. The next day all the code was done...
- «Usage Survey of Character Encodings broken down by Ranking» w3techs.com (Noiz kontsultatua: 2020-06-12).
Kanpo estekak
- Bell Labs-en 9. Planerako UTF-8 jatorrizko papera ( edo pdf )
- Andreas Prilop, Jost Gippert eta World Wide Web Partzuergoaren UTF-8 proba orriak
- Unix / Linux: UTF-8 / Unicode FAQ, Linux Unicode HOWTO, UTF-8 eta Gentoo
| Autoritate kontrola |
|
|---|
 Datuak: Q193537
Datuak: Q193537 Multimedia: Category:UTF-8 / Q193537
Multimedia: Category:UTF-8 / Q193537