Konputazio paralelo
Paralelismoa konputazio modu bat da, hainbat kalkulu aldi berean paraleloan egiten dituena,[1] problema handiak hainbat problema txikitan banatzeko printzipioan oinarrituta dago, gero problema txiki horiek paraleloan ebazteko. Paralelismoa urte askotan erabili da, batez ere Errendimendu Handiko Informatikarako.

Konputagailuek prozesadore bakar bat erabili ohi dute programa informatikoak eta aplikazioak exekutatzeko. Prozesadoreak, urteak pasa ahala, gero eta azkarragoak bihurtu dira, eta prozesadore bakar baten konputazio-ahalmena nahikoa izan ohi da eguneroko aplikazioetarako (adib., bulegotika, bideoa, argazkiak, jokoak). Hala ere, hainbat aplikaziotan, prozesadore bakar batekin lor daitekeen exekuzio-abiadura ez da nahikoa emaitzak behar den denbora-tartean eskuratzeko. Aplikazio horiek oso arlo desberdinetakoak izan daitezke: datu-base handiak kudeatzea (Google, esaterako), online merkataritzako zerbitzuak (Amazon...), irudien prozesamendua (zientzian zein zinema-industrian), ingeniaritzako eta zientzietako aplikazioak (eguraldiaren iragarpena, genetika, astrofisika, fisika kuantikoa eta nuklearra, kimika, farmazia, prozesuen simulazioak...) eta abar.

Exekuzio-abiadura handiagoak (100, 1.000, 10.000... aldiz handiagoak) lortzeko, irtenbide bakarra dago: aldi berean prozesadore asko modu koordinatuan erabiltzea, hau da, paralelismoa erabiltzea. Paralelismo hitzarekin hau adierazi nahi dugu: programa baten exekuzioa hainbat prozesadoreren artean banatzen dela, eta prozesadoreek paraleloan, batera, lan egiten dutela.[2][3]
Paralelismorako arkitektura desberdinak[2]

Prozesadore asko erabiltzen dituzten konputagailu paraleloek izen bat edo beste hartzen dute, baliabideak zein diren eta nola antolatzen diren arabera: superkonputagailuak, multiprozesadoreak, multikonputagailuak, klusterrak... Oro har, konputagailu paraleloak bi motatakoak dira: memoria partekatuko konputagailuak, non sistemako prozesadore guztiek memoria bera erabiltzen baitute; eta memoria banatuko konputagailuak, zeinetan prozesadore bakoitzak bere memoria pribatua erabiltzen baitu.

P prozesadore erabili behar badira aplikazio jakin bat exekutatzeko, lehenik eta behin, jatorrizko aplikazioa P prozesutan banatu behar da. Bi aukera nagusi (eta haien arteko konbinazioak) daude prozesu horiek sortzeko:
- Datu-paralelismoa ustiatzea. Prozesadore guztiek kode bera exekutatzen dute, baina "datu" desberdinen gainean. Adibidez, film baten 150.000 irudi prozesatu behar baditugu ehun prozesadoreko konputagailu batean, prozesadore guztiek lan bera egingo dute, baina bakoitzak 1.500 irudi baino ez ditu prozesatuko. Datu independente asko baldin badago prozesatzeko, exekuzio-abiadura handiak lor daitezke horrela.
- Funtzio-paralelismoa ustiatzea. Prozesadoreek ataza desberdinak exekutatzen dituzte. Adibidez, gune jakin baten eguraldiaren eboluzioaren simulazio batean, prozesadore batek itsasoaren portaera simula dezake, beste batek kostaldekoa, beste batek atmosferakoa, beste batek hiriguneetakoak eta abar, bakoitzak eredu desberdinak erabiliz. Eskuarki, paralelismo-mota honekin lortzen den paralelismo-maila ez da oso handia, zailagoa baita funtzio desberdin asko bereiztea aplikazioetan.
Lortzen den exekuzio-denbora[2]
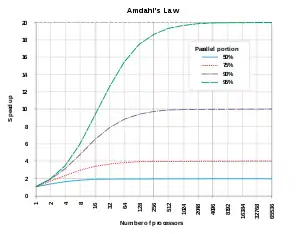

P prozesadoreko konputagailu paralelo baten helburua da aplikazioak P aldiz azkarrago exekutatzea, edo, baliokidea dena, P aldiz datu gehiago prozesatzea aurreko denbora berean. Aplikazio sinple batzuekin helburu hori lor badaiteke ere, eskuarki arazo asko daude helmuga horretara iristeko. Arazo nagusia paraleloan exekutatzen diren prozesuen arteko komunikazioa da. Oro har, prozesuak ez dira independenteak eta, haien datuez gain, besteen emaitzak ere erabili behar dituzte, lankidetzan ari baitira problema konplexu bati soluzio bat emateko. Konputagailuaren arkitekturaren arabera, bi aukera daude prozesuen arteko komunikazioa betetzeko.
Konputagailuaren memoria partekatua eta zentralizatua bada, sinkronizazio-funtzio bereziak erabili behar dira aldagai partekatuak atzitzeko. Adibide sinpleena ekoizle/kontsumitzaile exekuzio-ereduarena da: prozesu batzuek datuak ekoizten dituzte, eta beste batzuek datu horiek kontsumitu (erabili) behar dituzte; beraz, kontsumitzaileek zain egon behar dute (ezer egin gabe) ekoizleek datuak sortu arte, eta, oro har, ekoizleek ez dituzte datu gehiago sortuko aurrekoak kontsumitu diren arte.
Bestalde, memoria banatuta badago, prozesadoreek mezuak trukatu behar dituzte haien artean, datuak eskatzeko eta emateko. Mezu horiek sistemaren komunikazio-sarea erabili behar dute, eta komunikazio horrek denbora asko beharko du (komunikazioa kalkulua baino 1.000-10.000 aldiz motelagoa izan ohi da); ondorioz, konputagailu paralelo baten komunikazio-sarea prozesadore kpurua bezain garrantzitsua da.
Dela sinkronizazio-funtzioen bidez, dela mezu-ematearen bidez, aplikazioa paraleloan exekutatzeagatik ordaindu behar den "bidesaria" da prozesuen arteko komunikazioa. Gainera, sinkronizaziorako edo komunikaziorako behar den denbora prozesadore-kopuruaren arabera hazten da. Beraz, laburki (eta beste zenbait arazo kontuan hartu gabe), honela adieraz daiteke aplikazio baten exekuzio-denbora P prozesadore erabiltzen direnean:

non serieko exekuzio-denbora, eta prozesadoreen arteko komunikazioen denbora baitira.


Paralelismorako tresna estandarrak[2]
Azken urteotan, asko zabaldu da konputagailu paraleloen erabilera, eta aplikazio oso bat programatzeko tresnak estandarrak azaldu dira. Memoria partekatuko sistemetan, OpenMP izaten da gehien erabiltzen den tresna prozesadoreen arteko lan-banaketa eta sinkronizazioa zehazteko. Memoria banatuko sistemetan, ordea, estandarra MPI izaten da komunikazio-funtzioen liburutegia, zeinen bidez erabiltzaileak prozesuak nola eta noiz komunikatzen diren zehaztu behar duen. Paralelismoa gero eta gehiago erabiliko da; izan ere, teknologiaren eboluzioa dela eta, etxean ditugun ordenagailu pertsonalak ere multiprozesadoreak dira dagoeneko, bi (eta laster lau eta zortzi) nukleo dituzte eta. Bestalde, komunikazioetan gertatu diren aurrerapenak direla medio, geografikoki banatuta dauden konputagailuak konputagailu paralelo bakar gisa erabiltzeko aukera ere izango dugu (hori da, hain zuzen, The Grid izeneko proiektuaren helburua).
Aplikazioak[2]
Konputazio paraleloa gero eta azkarragoa bihurtzen ari denez, aurrez luze eta garestitzat jotzen ziren problema asko konpondu ahal dira gaur egun. Paralelismoa gai desberdin askotan erabiltzen da gaur egun da, Ohiko aplikazio paraleloak izaten dira datu-base handiak kudeatzea (Google, esaterako), online merkataritzako zerbitzuak (Amazon...), irudien prozesamendua (zientzian zein zinema-industrian), ingeniaritzako eta zientzietako aplikazioak (eguraldiaren iragarpena, genetika, astrofisika, fisika kuantikoa eta nuklearra, kimika, farmazia, prozesuen simulazioak...), bioinformatika (proteinen tolestura egiteko) ekonomia (finantza matematikan simulazioak egiteko), eta abar.
Teknikak
Paralelismoan erabiltzen diren teknika tipikoak hauek dira: [4]
- Monte Carlo simulazioa
- Logika konbinazionala ( indar gordinaren teknikak, esaterako)
- Grafikoa zeharkatzea
- Programazio dinamikoa
- Adarkatze eta inausketa metodoak
- Grafikoen eredua
- Automata finituen simulazioa
Erreferentziak
- Almasi, G.S. and A. Gottlieb (1989). Highly Parallel Computing. Benjamin-Cummings publishers, Redwood City, CA.
- Arruabarrena, Agustin. (2013). «Superkonputagailuak. Istorio luze-luze bat. — Unibertsitatea.Net» www.ueu.eus (Noiz kontsultatua: 2023-09-03).
- Arruabarrena, Agustin. (2015). «Paralelismo. ZT Hiztegi Berria» zthiztegia.elhuyar.eus (Elhuyar Fundazioa) (Noiz kontsultatua: 2021-02-10).
- Asanovic, Krste, et al. (December 18, 2006). The Landscape of Parallel Computing Research: A View from Berkeley (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. See table on pages 17-19.
Ikus, gainera
- Openmp
- OpenACC
- OpenCL
- CUDA
- Vulkan
- Zilka
- Intel TBB
- Agustin Arruabarrena
Kanpo estekak
| Wikiliburuetan liburu bat dago honi buruz: Distributed Systems |
- Konputazio paralelo artikulua DMOZ direktorioan
- Lawrence Livermore Laborategi Nazionala: Konputazio Paraleloaren Sarrera
- Programa paraleloak diseinatu eta eraikitzea, Ian Foster-en eskutik
- Interneteko Konputazio Paraleloaren Artxiboa
- IEEE Distributed Computing Online aldizkarian prozesaketa paraleloa gaia
- Parallel Computing Works liburua online
- Frontiers of Supercomputing liburua online. Algoritmoak eta industria-aplikazioak erakusten ditu.
- Universal Parallel Computing Research Center
- Course in Parallel Programming at Columbia University (in collaboration with IBM T.J. Watson X10 project)
- Parallel and distributed Gröbner bases computation in JAS, see also Gröbner basis
- Course in Parallel Computing at University of Wisconsin-Madison
- Berkeley Par Lab: progress in the parallel computing landscape, Editors: David Patterson, Dennis Gannon, and Michael Wrinn, August 23, 2013
- The trouble with multicore, by David Patterson, posted 30 Jun 2010
- Parallel Computing : A View From Techsevi
- Introduction to Parallel Computing
- Coursera: Parallel Programming
- Parallel Programming Tuts at AiTechtonic
| Autoritate kontrola |
|
|---|
 Datuak: Q232661
Datuak: Q232661 Multimedia: Parallel computing / Q232661
Multimedia: Parallel computing / Q232661