Common Voice
Common Voice crowdsourcing proiektu bat da (lankidetza-proiektua), Mozillak abiarazia, ahots-grabaziozko datu-base libre bat sortzeko, hainbat hizkuntzatan, eta hizketa ezagutzeko softwareetan erabili ahal da modu librean.[1] Boluntarioek mikrofono batekin grabatzen dituzte esaldiak, eta grabazioak beste erabiltzaile batzuek berrikusten dituzte. Transkribatutako esaldiak ahotsezko datu-base batean jasotzen dira, jabari publikozko lizentziapean.[2][3] Lizentzia horrek ziurtatzen du edozein garatzailek datu-basea erabil dezakeela ahotsetik testurako aplikazioetarako, mugarik edo kosturik gabe.
 | |
| Jatorria | |
| Sorrera-urtea | 2017 |
| Ezaugarriak | |
| Hizkuntza | eleaniztuna |
| Sarrera gailua | ukimen-pantaila |
| Egile-eskubideak | copyright, egile-eskubideen titularrak jabari publikoari eskainia |
| Lizentzia | CC0 |
| commonvoice.mozilla.org | |
Common Voice proiektua jakintza libreen ikuspuntutik Amazon-en Eco, Siri edo Google Assistant bezalako enpresa handien ahots-asistenteetarako alternatiba libre bat sortzen laguntzeko. Korporazio handiek erabiltzen dituzten datu gehienak ez daude jende gehienaren eskura. Horrek berrikuntza itotzen duela ikusita, Common Voice proiektuak ahotsaren ezagutza guztiei irekita uzten die. Edonork lagundu dezake bere ahotsa utziz ahots datu-base ireki bat eraikitzen laguntzeko, eta horrekin gailuetarako eta weberako app berritzaileak sortzen laguntzeko, proposatutako esaldi batzuk benetako hiztun batek nola hitz egiten duen makinei irakasteko. Bestalde, beste laguntzaileen lanaren kalitatea egiaztatzen ere lagundu dezake edonork.[1]
Common Voice datuez gain, kode irekiko ahotsa ezagutzeko Deep Speech motorra ere ari dira eraikitzen.[4]
Ahotsen datu-basea
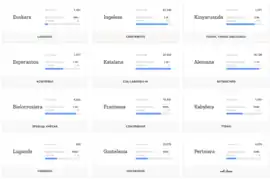
Common Voice datu-basea libre ingeleserako erabil daitekeen bigarren ahots-datu base handiena da, LibriSpeech-en atzetik. 2017ko azaroaren 29an datuak lehen aldiz argitaratu zirenean, mundu osoko 20.000tik gora erabiltzailek 400,000 esaldi zituen, grabatuta eta baliozkotuta, guztira 500 orduko iraupenarekin.[5]
2019ko otsailean liberatu ziren hizkuntza erabilgarrien lehen loteak. 18 hizkuntza sartu zituen: ingelesa, frantsesa, alemana eta txinera, baina baita beste hizkuntza batzuk ere, hala nola galesa eta cabilenc. Guztira, ia 1,400 ordu sartu zituen 42,000 kolaboratzaile baino gehiagoren ahots-datuetarako.[6]
Euskarazkoa datu-baserako grabazioak egiteko aukera 2019ko apirilean zabaldu zen. 2022ko apirilean, euskarazko 1.200 parte hartzaile izatera ailegatu zen, eta 99 ordu zeuden baliozkotuta.[7]
Katalanaren kasuan, 2018ko ekainean hizkuntza guztietara zabaldu eta gutxira, Softcatalà elkarteak katalanerako proiektuari ekin zion.[8] 2022ko otsailean, katalanak 27.000 parte hartzaile hartu ditu, 1.000 ordu baino gehiago ditu grabatuta eta 900 ordu baliozkotuta, euskaraz baina 10 aldiz gehiago.[9]
Grabazioaren funtzionamendua
Euskararen kasuan, 5.000 esaldiko corpus batekin trebatzen da datu-basea. Ez 5.000 grabaketa lortu eta kito, baizik eta esaldi bakoitza ahalik eta lagun gehienek grabatzeko saioa egin da. Eta norberak grabatzeaz gain, beste ahots batzuekin esandakoak balioztatzea ere bada kontua.[10]
Nabigatzailearen bidez funtzionatzen du Common Voicek. PC ordenagailuan edo telefonoaren bidez. Audio grabaketaren kalitatea ez da akaso onena izango, baina pentsa dezagun ere testuinguru horretan funtzionatu beharko duela gero teknologia: telefono bati, edo etxeko tresnaren bati egongelan egin beharko diogula euskaraz egunen batean.[10]
Erreferentziak
- «Mozilla Common Voice. Webgune ofiziala» commonvoice.mozilla.org (Noiz kontsultatua: 2022-04-23).
- «Mozilla Common Voice - Grabazioen baldintzak» commonvoice.mozilla.org (Noiz kontsultatua: 2023-11-15).
- (Ingelesez) «Mozilla Common Voice. Datasets (datuak jasotzeko webgunea)» commonvoice.mozilla.org (Noiz kontsultatua: 2022-04-23).
- A TensorFlow implementation of Baidu's DeepSpeech architecture: mozilla/DeepSpeech. 2019-12-08.
- White, Sean. Announcing the Initial Release of Mozilla’s Open Source Speech Recognition Model and Voice Dataset. .
- Mozilla updates Common Voice dataset with 1,400 hours of speech across 18 languages. 2019-02-28.
- (Ingelesez) «Mozilla Common Voice» commonvoice.mozilla.org (Noiz kontsultatua: 2022-04-23).
- Jané, Carmen. (2018-08-12). Softcatalà i Mozilla impulsen un assistent de veu lliure en català. .
- El català supera les 1.000 hores enregistrades al projecte Common Voice. 2022-02-11.
- «Nola elikatu Common Voice euskarazko ahots-ezaguera automatikoa hedatzeko» sustatu.eus (Noiz kontsultatua: 2022-04-23).
Ikus, gainera
Kanpo estekak
- Common Voice Webgune ofiziala euskaraz.
| Autoritate kontrola |
|
|---|
 Datuak: Q44106011
Datuak: Q44106011 Multimedia: Common Voice / Q44106011
Multimedia: Common Voice / Q44106011