Trendmodell
Das Trend-Saison-Modell ist der traditionelle Ansatz der Zeitreihenanalyse. Die Modellierung erfolgt mit Hilfe eines mathematischen Modells, das folgende Komponenten umfasst:
- eine Trendkomponente,
- eine Saisonkomponente und
- eine Rauschkomponente.
Fehlt z. B. die Saisonkomponente, so spricht man auch nur von einem Trendmodell.
Modellaufbau
Wenn die beobachtete Zeitreihe ist, dann wird zunächst ein Trend geschätzt. Möglich sind lineare, polynomiale oder exponentielle Trends, aber auch gleitende Durchschnitte.


Aus den Residuen kann man eine additive oder multiplikative Saisonkomponente schätzen. Dabei wird davon ausgegangen, dass die Abweichungen der Trendfunktion von den beobachteten Werten einem saisonalen Muster unterliegen.

Beispiel
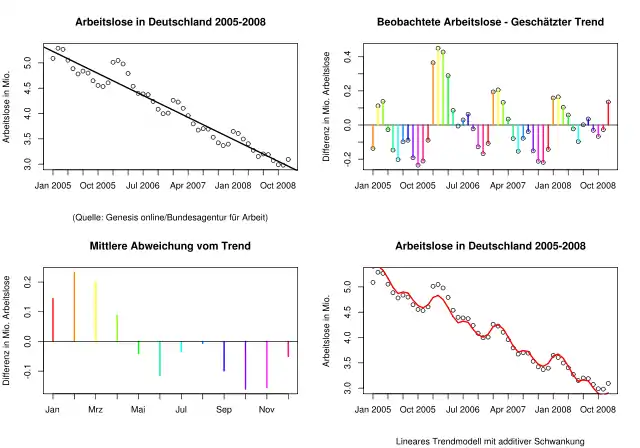
Die Grafik unten zeigt die Arbeitslosenzahlen in der Bundesrepublik Deutschland von Januar 2005 bis Dezember 2008 (links oben) und eine lineare Trendfunktion. Rechts oben wird die Abweichung zwischen den beobachteten Arbeitslosenzahlen und den Schätzungen aus dem Trend gezeigt. Man sieht, dass im Frühjahr jeden Jahres die Trendfunktion die Arbeitslosenzahlen unterschätzt und im Herbst überschätzt (gleiche Farbe = gleicher Monat). Die Grafik links unten zeigt die über die Jahre gemittelte Abweichung für jeden Monat. Diese Abweichung wird für den entsprechenden Monat zur Trendfunktion addiert. Damit ergibt sich in der Grafik rechts unten das Trend-Saison-Modell (rote Linie).
Trendschätzung

Der Trend einer Zeitreihe gibt den globalen Verlauf einer Zeitreihe wieder. Dafür werden verschiedene Regressionsansätze verwendet:
- ein lineares oder polynomiales Modell: ,
- ein exponentielles Modell: oder
- auch gleitende Durchschnitte mit einer entsprechend hohen Ordnung.


Lineares oder polynomiales Trendmodell
Im linearen oder polynomialen Trendmodell wird einfach eine lineare oder polynomiale Regression bzgl. der Zeitvariablen durchgeführt, um den Trend zu schätzen:
Während die geschätzten Werte , , ... davon abhängen, wie die Zeit parametrisiert wird, sind die geschätzten Trendwerte unabhängig von der Parametrisierung.



Die folgende Tabelle zeigt zwei Parametrisierungen der Zeit für ein lineares Trendmodell:
- beim ersten Trendmodell entspricht
- Januar 2005 gleich und
- Februar 2005 gleich ,
- beim zweiten Trendmodell entspricht
- Januar 2005 gleich und
- Februar 2005 gleich .




Danach liegen die Werte für bzw. für alle folgenden Monate fest.


| Arbeitslose | Lineares Trendmodell 1 | Lineares Trendmodell 2 | |||
|---|---|---|---|---|---|
| Zeitpunkt | (in Mio.) | ||||
| Jan 2005 | 5,09 | 1 | 4,80 | −83 | 4,80 |
| Feb 2005 | 5,29 | 2 | 4,77 | −81 | 4,77 |
| Mrz 2005 | 5,27 | 3 | 4,75 | −79 | 4,75 |
| ... | ... | ... | ... | ... | ... |
| Dez 2011 | 2,78 | 84 | 2,63 | +83 | 2,63 |
| Trendmodell | |||||




Da bei den beiden Parametrisierungen die gleichen Schätzwerte herauskommen, kann man irgendeine wählen:
- Die erste Parametrisierung erlaubt eine leichte Interpretation der Trendfunktion . Ausgehend von einer Arbeitslosenzahl von 4,825 Mio. im Dezember 2004 () fällt die Arbeitslosenzahl durchschnittlich um ca. 26.150 Personen pro Monat bis Dezember 2011.
- Die zweite Parametrisierung wäre nützlich, wenn man die Regressionskoeffizienten von Hand ausrechnen müsste. Dabei wird unter anderem das arithmetische Mittel benötigt, das sich hier zu ergibt. Des Weiteren sieht man, dass im Durchschnitt 3,71363 Mio. Menschen im Zeitraum Januar 2005 bis Dezember 2011 arbeitslos waren.



Bei den vorliegenden Daten wäre jedoch eine lineare Trendfunktion ungeeignet, da sie den globalen Verlauf der Zeitreihe nur schlecht wiedergibt. Dies zeigt auch die vorhergehende Grafik. Sie zeigt auch, dass eine quadratische Trendfunktion besser wäre:
- .

Exponentielles Modell

Ein exponentielles Trendmodell kommt zum Einsatz, wenn die Daten es nahelegen. In der rechten Grafik sehen wir die Anzahl der Telefone (in Tsd.) in den USA von 1891 bis 1979 sowie eine exponentielle und eine lineare Trendfunktion. Offensichtlich beschreibt der exponentielle Trend die Daten besser als der lineare Trend.
Des Weiteren hat das exponentielle Trendmodell

den Vorteil, dass bei der Rückrechnung sich ergibt
- .

Der geschätzte Wert für jedes .


Die Schätzung der Regressionskoeffizienten erfolgt durch Rückführung auf das lineare Modell, d. h. sowohl als auch werden logarithmiert und dann und geschätzt.


Im Gegensatz zur linearen oder polynomialen Trendfunktion hängen sowohl die Werte der geschätzten Regressionskoeffizienten als auch der Schätzwerte davon ab, wie die Zeit parametrisiert wird. In der Grafik entspricht das Jahr 1891 gleich und das Jahr 1892 gleich


- .

Gleitende Durchschnitte
Eine weitere Alternative zur Trendschätzung sind gleitende Durchschnitte mit genügend hoher Ordnung . Dabei wird an einer Stelle der Wert als Durchschnitt der Beobachtungswerte berechnet. Unterschieden werden muss die Berechnung für gerade und ungerade Ordnungen:



Bei einer geraden Ordnung fließen die Randpunkte und jeweils mit dem Gewicht 1/2 ein und alle Punkte zwischen ihnen mit dem Gewicht 1.


Dies ist jedoch nur eine Möglichkeit, gleitende Durchschnitte zu berechnen; für weitere siehe den Hauptartikel Gleitender Mittelwert.

Die gleitende Durchschnitte werfen jedoch drei Probleme auf:
- Welche Ordnung sollte man für die Trendschätzung wählen? Ist die Ordnung zu klein, dann fängt der gleitende Durchschnitt unter Umständen auch die Saisonalität der Daten ein. Ist die Ordnung zu groß, dann passt sich der Trend nicht mehr so gut an die Daten an. Die Grafik zeigt verschiedene Ordnungen: Sieben entspricht einem Quartal vorher und nachher, Dreizehn entspricht einem halben Jahr vorher und nachher und fünfundzwanzig entspricht einem Jahr vorher und nachher.
- An den Rändern, also Januar 2005 bzw. Dezember 2011 in der nebenstehenden Grafik, kann man keine Schätzwerte mehr berechnen, da in dem Datensatz weder Werte vor dem Januar 2005 noch nach dem Dezember 2011 vorliegen.
- Beim linearen, polynomialen und exponentiellen Trendmodell kann man prinzipiell auch in die Zukunft extrapolieren. Dies ist bei einem gleitenden Durchschnitt nicht möglich, da dafür bereits die zukünftigen Werte bekannt sein müssten. Er eignet sich also nur zur Beschreibung der Daten.
Der Vorteil der gleitenden Durchschnitte ist jedoch die bessere Anpassung an einen nicht-linearen Trend in den Daten.
Saisonschätzung
Bei der Saisonschätzung geht man davon aus, dass es eine Struktur in der Zeitreihe gibt, die sich saisonal wiederholt. Die Länge einer Saison ist dabei vorab bekannt. Bei den Arbeitslosenzahlen weiß man, dass aufgrund der Witterungsbedingungen die Arbeitslosenzahlen zum Winter hin regelmäßig ansteigen, während sie zum Sommer hin wieder fallen. Es gibt also ein jährliches Muster in den Daten.
Im Wesentlichen werden Saisonschwankungen entweder additiv oder multiplikativ modelliert:

Mit der Wert aus einer Trendschätzung und ein Index, der sich in jeder Saison wiederholt.

Die folgende Tabelle zeigt die Werte der Arbeitslosenzahlen in Deutschland von Januar 2005 bis Dezember 2011 (), eine Trendschätzung () mit einem gleitenden Durchschnitt der Ordnung 13 sowie die Abweichungen zwischen den Beobachtungswerten und der Trendschätzung für ein additives bzw. multiplikatives Saisonmodell.
| Zeitpunkt | Arbeitslose | Trendschätzung | Add. Abweichung | Mult. Abweichung | |
|---|---|---|---|---|---|
| (in Mio.) | (Gl. Ø mit ) | ||||
| Jan 2005 | 5,09 | -- | -- | -- | 1 |
| Feb 2005 | 5,29 | -- | -- | -- | 2 |
| Mrz 2005 | 5,27 | -- | -- | -- | 3 |
| Apr 2005 | 5,05 | -- | -- | -- | 4 |
| Mai 2005 | 4,88 | -- | -- | -- | 5 |
| Jun 2005 | 4,78 | -- | -- | -- | 6 |
| Jul 2005 | 4,84 | 4,87 | −0,04 | 0,993 | 7 |
| Aug 2005 | 4,80 | 4,87 | −0,07 | 0,985 | 8 |
| Sep 2005 | 4,65 | 4,85 | −0,20 | 0,959 | 9 |
| Oct 2005 | 4,56 | 4,81 | −0,25 | 0,947 | 10 |
| Nov 2005 | 4,53 | 4,77 | −0,24 | 0,950 | 11 |
| Dez 2005 | 4,60 | 4,73 | −0,13 | 0,973 | 12 |
| Jan 2006 | 5,01 | 4,70 | +0,31 | 1,066 | 1 |
| Feb 2006 | 5,05 | 4,67 | +0,38 | 1,082 | 2 |
| Mrz 2006 | 4,98 | 4,62 | +0,35 | 1,077 | 3 |
| Apr 2006 | 4,79 | 4,58 | +0,21 | 1,046 | 4 |
| Mai 2006 | 4,54 | 4,54 | 0,00 | 1,000 | 5 |
| Jun 2006 | 4,40 | 4,50 | −0,10 | 0,978 | 6 |
| Jul 2006 | 4,39 | 4,47 | −0,08 | 0,981 | 7 |
| Aug 2006 | 4,37 | 4,41 | −0,04 | 0,991 | 8 |
| Sep 2006 | 4,24 | 4,34 | −0,10 | 0,977 | 9 |
| Oct 2006 | 4,08 | 4,26 | −0,17 | 0,959 | 10 |
| Nov 2006 | 4,00 | 4,18 | −0,19 | 0,955 | 11 |
| Dez 2006 | 4,01 | 4,12 | −0,11 | 0,974 | 12 |
| ... | ... | ... | ... | ... | ... |



Additive Saisonschwankung
Jedem Zeitpunkt einer Saison mit einer vorgegebenen Länge wird ein Saisonindex zugeordnet. Dann wird die Differenz zwischen dem Beobachtungswert und dem geschätzten Trendwert gebildet



- .

Danach werden für ein fixes alle Werte gemittelt

In dem Arbeitslosenbeispiel () werden zunächst also alle Januarabweichungen gemittelt ():



Dies wird für alle Monate wiederholt bis Dezember ():


Damit kann aus der Trendschätzung und den gemittelten Saisonabweichungen die endgültige Zeitreihenschätzung berechnet werden.

| Zeitpunkt | ||||||
|---|---|---|---|---|---|---|
| Jan 2005 | 5,09 | -- | -- | 1 | -- | -- |
| ... | ... | ... | ... | ... | ... | ... |
| Dez 2005 | 4,60 | 4,73 | −0,13 | 12 | −0,12 | 4,61 |
| Jan 2006 | 5,01 | 4,70 | 0,31 | 1 | 0,23 | 4,93 |
| ... | ... | ... | ... | ... | ... | ... |
| Dez 2006 | 4,01 | 4,12 | −0,11 | 12 | −0,12 | 4,00 |
| Jan 2007 | 4,26 | 4,06 | 0,20 | 1 | 0,23 | 4,29 |
| ... | ... | ... | ... | ... | ... | ... |

Multiplikative Saisonschwankung
Jedem Zeitpunkt einer Saison mit einer vorgegebenen Länge wird ein Saisonindex zugeordnet. Dann wird der Quotient zwischen dem Beobachtungswert und dem geschätzten Trendwert gebildet
- .

Danach werden für ein fixes alle Werte gemittelt.

In dem Arbeitslosenbeispiel () werden zunächst also alle Januarabweichungen gemittelt ():

Dies wird für alle Monate wiederholt bis Dezember ():

Damit kann aus der Trendschätzung und den gemittelten Saisonabweichungen die endgültige Zeitreihenschätzung berechnet werden.
| Zeitpunkt | ||||||
|---|---|---|---|---|---|---|
| Jan 2005 | 5,09 | -- | -- | 1 | -- | -- |
| ... | ... | ... | ... | ... | ... | ... |
| Dez 2005 | 4,60 | 4,73 | 0,973 | 12 | 0,967 | 4,58 |
| Jan 2006 | 5,01 | 4,70 | 1,066 | 1 | 1,063 | 5,00 |
| ... | ... | ... | ... | ... | ... | ... |
| Dez 2006 | 4,01 | 4,12 | 0,974 | 12 | 0,967 | 3,98 |
| Jan 2007 | 4,26 | 4,06 | 1,049 | 1 | 1,063 | 4,32 |
| ... | ... | ... | ... | ... | ... | ... |

Güte eines Trend-Saison-Modells
Da es verschiedene Möglichkeiten sowohl für die Trendschätzung als auch für die Saisonschätzung gibt, stellt sich die Frage, welches Modell das beste ist. Da beide Modelle nicht-linear sein können, kann man nicht unbedingt zweistufig vorgehen, d. h. erst das „beste“ Trendmodell nehmen und danach das beste Saisonmodell auswählen; nur eine Kombination von Trend- und Saisonschätzung sollte geprüft werden.
In Anlehnung an die lineare Regression wird ein Bestimmtheitsmaß für ein Trend-Saison-Modell definiert:

mit der Mittelwert aller , für die eine Vorhersage gemacht wird. In der Regel ist das Bestimmtheitsmaß eines Trend-Saison-Modells deutlich größer als in der linearen Regression.

Die folgende Tabelle zeigt für die Arbeitslosendaten in Deutschland von Januar 2005 bis Dezember 2011 die Bestimmtheitsmaße für verschiedene Trend- bzw. Trend-Saison-Modelle.
| Trendmodell | Linear | Exponentiell | Gl. Durchschnitt () | |||
|---|---|---|---|---|---|---|
| 0,817 | 0,765 | 0,917 | ||||
| Saisonschwankung | additiv | multiplikativ | additiv | multiplikativ | additiv | multiplikativ |
| 0,868 | 0,870 | 0,791 | 0,767 | 0,993 | 0,994 | |

Die Grafik zeigt die neun Trend-Saison-Modelle. Man sieht, dass sowohl die blauen (linearer Trend) als auch die grünen Modelle (exponentieller Trend) nicht gut zu den Daten passen. Die roten Modelle (gleitende Durchschnitte) passen am besten zu den Daten.

Literatur
- Peter P. Eckstein: Statistik für Wirtschaftswissenschaftler: Eine realdatenbasierte Einführung mit SPSS. 2. Auflage. Gabler Verlag, 2010, ISBN 978-3-8349-2345-5.