External Memory Algorithmus
Ein External Memory Algorithmus (auch Out-of-Core Algorithmus) ist ein Algorithmus, der darauf optimiert ist, Datenmengen effizient zu verarbeiten, welche die Kapazität des verfügbaren Hauptspeichers übersteigen. Zugriffe auf Massenspeicher wie Festplatten oder Netzwerkspeicher sind aber um mehrere Größenordnungen langsamer als Operationen der ALU oder Zugriffe auf höhere Ebenen der Speicherhierarchie. Deshalb ist für die Performance von External Memory Algorithmen die Anzahl der I/O-Operationen auf langsamen Massenspeichern maßgeblich.
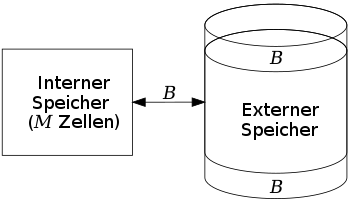



Analyse im Parallel Disk Model (PDM)
Zur Analyse von External Memory Algorithmen wird häufig das Parallel Disk Model verwendet. Es modelliert die wichtigsten Eigenschaften von magnetischen Festplatten und Systemen mit mehreren parallel angebundenen Festplatten und ist trotzdem einfach genug für eine effiziente Analyse.[1] Wir betrachten hier nur batch-Probleme und Systeme mit einem Prozessor. Für online-Probleme und Systeme mit beliebiger Anzahl Prozessoren siehe Vitter (2006).[1]
Definition
Das Modell besteht aus einem internen Speicher welcher Datenelemente fasst, sowie einem unbegrenzten externen Speicher welcher aus Festplatten besteht. Der wesentliche Performance-Indikator ist die I/O-Komplexität: die Anzahl von Zugriffen auf den externen Speicher zur Lösung eines Problems mit Datenelementen. Bei jedem Zugriff auf den externen Speicher kann von jeder der Festplatten ein Block von Datenelementen in den internen Speicher geladen werden. Analog kann vom internen in den externen Speicher geschrieben werden. Des Weiteren soll gelten sowie .[1]






Bei Festplatten müssen für eine effiziente Verarbeitung die Eingabedaten des Problems im striped Format auf den Platten verteilt vorliegen (siehe die nebenstehende Abbildung für ein Beispiel). Die Ausgabe des Algorithmus soll dem gleichen Format folgen. Hierdurch können Datenelemente mit der optimalen Anzahl von I/Os in den externen Speicher geschrieben oder von ihm gelesen werden.[1]


Oft können die Formeln der resultierenden Anzahl von I/Os vereinfacht werden, wenn statt der oben verwendeten Größen in Anzahl von Datenelementen die jeweilige Größe in Anzahl von Blöcken verwendet werden. Hieraus ergeben sich die abgeleiteten Größen sowie .[1]


Fundamentale Operationen
Die I/O-Komplexität vieler Algorithmen wird im Wesentlichen bestimmt durch die Performance einiger fundamentaler Operationen[1]:
- Scanning (auch streaming oder touching) – Lesen oder schreiben von sequentiellen Datenelementen
- Sortieren von Datenelementen (vergleichsbasiert)
Schranken für die I/O-Komplexität dieser Operationen finden sich in folgender Tabelle:
| Operation | I/O-Schranke, D = 1 | I/O-Schranke, D ≥ 1 |
|---|---|---|






Beispiele
Merge Sort
Als ein einfaches Beispiel für einen I/O-optimalen External Memory Sortieralgorithmus soll External Memory Merge Sort mit dienen. Dieser Algorithmus arbeitet in zwei Phasen.[1]

Die erste Phase namens run formation erhält als Eingabe eine unsortierte Folge von Elementen im externen Speicher und erzeugt als Ausgabe ebendort eine Permutation dieser Folge, partitioniert in sortierte Teilfolgen der Länge (die sogenannten runs). Jede dieser Teilfolgen wird erzeugt, indem der Eingabeblöcke in den internen Speicher eingelesen, dort sortiert und anschließend wieder zurück in den externen Speicher geschrieben werden.[1]



In der zweiten Phase des Algorithmus werden die existierenden runs rekursiv verschmolzen bis nur noch ein vollständig sortierter run existiert. Dazu werden pro Rekursionsebene jeweils runs gleichzeitig Blockweise durch den internen Speicher gestreamt, und dabei zu einem sortierten run verschmolzen. Pro Ebene werden alle Elemente je einmal gelesen und geschrieben, was I/Os entspricht. Nach Merge-Phasen ist nur noch ein sortierter run übrig, das Ergebnis.[1]


Insgesamt benötigt der Algorithmus also I/Os und ist somit optimal.[1]

Motivation
Klassischerweise wird die Laufzeit von Algorithmen in Berechnungsmodellen ohne Speicherhierarchie analysiert. In diesen Modellen verursacht ein Speicherzugriff konstante Kosten, genau wie die Ausführung arithmetischer Befehle. Des Weiteren sind die Kosten eines Speicherzugriffs unabhängig von der Adresse auf die zugegriffen wird, sowie von vorangegangenen Zugriffen.[1]
Diese Annahmen sind vereinfachend und entsprechen nicht der Realität. Einerseits unterscheiden sich die Zugriffszeiten zwischen zwei Ebenen der Speicherhierarchie für gewöhnlich um Größenordnungen. Andererseits führen Caches sowie die Funktionsweise von Festplatten dazu, dass der Zugriff auf mehrere aufeinander folgende Adressen in der Regel schneller ist, als der Zugriff auf zufällige Adressen (siehe auch Lokalitätseigenschaft).[1]
Zwischen Haupt- und Massenspeicher ist der Unterschied zwischen den Zugriffszeiten besonders hoch.[1] Siehe dazu auch Speicherhierarchie. Dies trifft auch für SSDs als Massenspeicher zu.[2]
Anwendung
Es existieren diverse Bibliotheken und Tools um External Memory Algorithmen zu implementieren. Ein umfassende Übersicht ist in Vitter (2006) ab Seite 141 zu finden.
Geschichte
Laut Vitter[1] begann die Arbeit an External Memory Algorithmen bereits 1956 in Stanford mit H. B. Demuths Dissertation Electronic data sorting.[3] Auch Donald E. Knuth beschäftigte sich in seiner 1973 veröffentlichte Monografie The Art of Computer Programming – Volume 3: Sorting and Searching ausgiebig mit dem Sortieren von Daten auf Magnetbändern und zum Teil auch auf Festplatten.[4] Etwa zur selben Zeit präsentierte Robert W. Floyd in seiner Arbeit Permuting Information in Idealized Two-Level Storage ein Modell mit großer Ähnlichkeit zu PDM mit Parametern , , wobei .[5] 1988 erweiterten Aggarwal und Vitter in The input/output complexity of sorting and related problems Floyds Modell um die Möglichkeit von parallelen Block-Transfers.[6] 1994 führten Vitter und Shriver das Parallel Disk Model ein, welches eine realitätsnähere Version von Aggarwal und Vitters Modell darstellt.[7]



Siehe auch
- Speicherhierarchie
- Cache-Oblivious Algorithmus – für eine alternative Modellierung, bei der dem Algorithmus und nicht zur Verfügung stehen
Einzelnachweise
- Jeffrey Scott Vitter: Algorithms and Data Structures for External Memory. In: Foundations and Trends® in Theoretical Computer Science. Band 2, Nr. 4, 2006, ISSN 1551-305X, S. 305–474, doi:10.1561/0400000014 (nowpublishers.com [abgerufen am 26. Juli 2019]).
- Deepak Ajwani, Itay Malinger, Ulrich Meyer, Sivan Toledo: Characterizing the Performance of Flash Memory Storage Devices and Its Impact on Algorithm Design. In: Experimental Algorithms. Band 5038. Springer Berlin Heidelberg, Berlin, Heidelberg 2008, ISBN 978-3-540-68548-7, S. 208–219, doi:10.1007/978-3-540-68552-4_16 (springer.com [abgerufen am 30. Juli 2019]).
- Demuth, Howard B.: Electronic data sorting. Department of Electrical Engineering, Stanford University, 1956, OCLC 25124024.
- Knuth, Donald Ervin: The Art of Computer Programming. Vol. 3, Sorting and Searching. Addison-Wesley, 1973, ISBN 0-201-89685-0.
- Robert W. Floyd: Permuting Information in Idealized Two-Level Storage. In: Complexity of Computer Computations. Springer US, Boston, MA 1972, ISBN 1-4684-2003-8, S. 105–109, doi:10.1007/978-1-4684-2001-2_10.
- Alok Aggarwal, Jeffrey, S. Vitter: The input/output complexity of sorting and related problems. In: Communications of the ACM. Band 31, Nr. 9, 1. August 1988, S. 1116–1127, doi:10.1145/48529.48535.
- J. S. Vitter, E. A. M. Shriver: Algorithms for parallel memory, I: Two-level memories. In: Algorithmica. Band 12, Nr. 2-3, 1994, ISSN 0178-4617, S. 110–147, doi:10.1007/BF01185207 (springer.com [abgerufen am 26. Juli 2019]).