Merkmalexploration
Die Merkmalexploration ist ein interaktiver Algorithmus der Formalen Begriffsanalyse zum Finden von Implikationen zwischen Merkmalen von Daten. Der Algorithmus berechnet eine vollständige und minimale Stammbasis, aus der alle im untersuchten Gebiet geltenden Implikationen gefolgert werden können.
Idee
Ziel der Merkmalexploration ist es, alle möglichen Merkmalkombinationen in einem speziellen Sachbereich zu beschreiben, d. h. die Merkmallogik zu finden. Dieser Sachbereich ist durch einen formalen Kontext gegeben, der grundlegenden Datenstruktur der Formalen Begriffsanalyse. In dieser Kreuztabelle sind Beziehungen zwischen Gegenständen und Merkmalen verzeichnet. Mit Hilfe von Implikationen – in einer Erweiterung auch Klauseln – werden Abhängigkeiten und Zusammenhänge seitens der Merkmale erklärt.
Die Hauptaufgabe ist es eine Stammbasis zu bestimmen. Dabei geht man von einer Sammlung von Beispielen aus, die in einem Teilkontext gegeben sind. Der Algorithmus schlägt in einer eindeutig bestimmten Reihenfolge einem Experten (oder einem unterstützenden Programm) im Teilkontext geltende Implikationen vor. Akzeptiert der Experte diese, werden sie in die Stammbasis aufgenommen. Im anderen Fall muss der Experte ein Gegenbeispiel liefern, d. h. eine neue Zeile des Kontexts. So können selbst unendliche Mengen von Objekten (bei endlicher Merkmalmenge) untersucht werden.
Es ist auch möglich, für einen gegebenen Datensatz automatisch die Stammbasis zu berechnen; dann werden alle vorgeschlagenen Implikationen akzeptiert.
Mathematische Grundlagen
Pseudohüllen
Sei ein Hüllenoperator auf der (endlichen) Merkmalsmenge M. Eine Teilmenge heißt Pseudohülle genau dann wenn sie die folgenden Bedingungen erfüllt:


- ,
- enthält die Hülle jeder Pseudohülle , die echte Teilmenge von ist.




Implikationen und Stammbasis
Eine Implikation auf einer Menge M ist ein Paar von Teilmengen von M. Notation: .

Eine Teilmenge respektiert eine Implikation , wenn oder gilt.



gilt in einem formalen Kontext , wenn jeder Gegenstandsinhalt (also jede Zeile des Kontexts) die Implikation respektiert.


Eine Implikation folgt aus einer Menge von Implikationen per Definition genau dann, wenn in jedem formalen Kontext gilt, in dem auch jede Implikation aus gültig ist.

Betrachtet man die Menge aller Implikationen, die auf einem Kontext gelten, stellt sich die Frage ob es eine Teilmenge gibt, die alle diese Implikationen repräsentiert. Eine solche Basis muss folgende Bedingungen erfüllen:
- Jede Implikation aus gilt im formalen Kontext (Korrektheit).
- Jede Implikation, die im Kontext gilt, folgt aus (Vollständigkeit).
- Keine Implikation folgt aus den übrigen Implikationen, also aus (Irredundanz).


Vincent Duquenne und Jean-Louis Guigues haben gezeigt, dass für endliche Merkmalmengen eine solche Basis existiert.[1] Sie ist sogar eindeutig bestimmbar und von minimaler Kardinalität unter allen möglichen Implikationenbasen. Hierfür gibt es verschiedene Bezeichnungen: Stammbasis, kanonische Basis oder auch D-G-Basis.
Die Stammbasis eines formalen Kontextes ist die Menge der Implikationen .

Beispiel
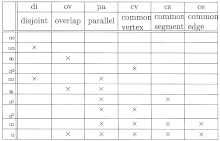

- Der Ausgangspunkt ist ein meist unvollständiger oder auch leerer Teilkontext.
- Der Algorithmus schlägt im Teilkontext geltende Implikationen vor. Der Experte kann sie akzeptieren oder ein Gegenbeispiel angeben:

- ce → pa, cv, cs: akzeptiert
- cs → pa: akzeptiert
- pa, cv, cs → ce: akzeptiert
- ov, cv → pa, cs, ce: Gegenbeispiel – neuer Gegenstand mit Merkmalen ov und cv
- ov, pa, cs → cv, ce: Gegenbeispiel – neuer Gegenstand mit Merkmalen ov, pa und cs
- ov, pa, cv → cs, ce: akzeptiert
- di, cv → alle Merkmale (widersprüchliche Prämisse, die entsprechende Gegenstandsmenge ist leer): akzeptiert
- di, pa, cs → alle Merkmale: akzeptiert
- di, ov → alle Merkmale: akzeptiert
- Die vom Experten akzeptierten Implikationen bilden die Stammbasis.
- Die Begriffsinhalte des erweiterten Kontexts und damit der Begriffsverband sind durch diese eindeutig bestimmt.
Exploration mit Hintergrundwissen

Die Stammbasis[2] zum nebenstehenden Beispiel ist








Dies ist allerdings eine etwas komplizierte Form, die einfache Äquivalenz auszudrücken:

Nur diese beiden Implikationen erhält man als Stammbasis, wenn man die Negation der Merkmale bestanden / nicht bestanden durch die Implikation sowie die Vollständigkeit der Information durch die Klausel dem Algorithmus als Startwissen übergibt, analog für die anderen Merkmale P und T.


Verfügt man also über Hintergrundwissen, kann die Merkmalexploration abgekürzt und die Stammbasis verkleinert werden. So kann etwa eine Menge von kumulierten Klauseln verwendet werden, die ausdrucksstärker als Implikationen sind. Die Stammbasis besteht dann aus einer Menge von Implikationen jeweils mit Prämissen P, die unter dem Hintergrundwissen abgeschlossen sind, also alle Merkmale enthalten, die durch das Hintergrundwissen gefordert sind. Für Implikationen als Hintergrundwissen bedeutet das eine wiederholte Anwendung des wie folgt definierten -Operators auf P:



Die gültigen Implikationen des zugrunde liegenden Kontexts können dann aus gefolgert werden.[3] Diese Stammbasis bezüglich eines durch das Hintergrundwissen definierten „relativen Testkontexts“ ist allerdings nicht in jedem Fall eindeutig bestimmt.[4]

Anwendungsgebiete
Mit Hilfe der Merkmalexploration lassen sich Datensätze auf Vollständigkeit überprüfen, Funktionale Abhängigkeiten sowie Assoziationsregeln finden und in kompakter Form darstellen, oder in Beschreibungslogiken ausgedrückte Wissensbasen vervollständigen[5]. Eine Anwendung in der Systembiologie zielt mittels Integration von Wissen und experimentellen Daten auf Prozessregeln für genregulatorische und andere Netzwerke.[6] In der Mathematik dient die Merkmalexploration dem Strukturieren von Beweisen.
Software
- Concept Explorer: Einfach zu bedienendes, grafisches Java-Programm mit den wichtigsten Funktionen, einschließlich Erzeugen eines Begriffsverbands. Die Eingabe von Hintergrund-Implikationen beim Aufruf aus einem eigenen Java-Programm ist möglich.
- Conexp-ng: Erweiterbare Java-Neuimplementierung von Concept Explorer.
- Conexp-clj: Neuimplementierung im Java-basierten Lisp-Dialekt Clojure. Insbesondere für Kommandozeilen-Aufruf und skriptbasierte Programmierung geeignet, mit erweiterten Möglichkeiten wie Luxenburger-Basen, Kontext-Automorphismen (Symmetrien der Merkmale), Fuzzy-FCA oder einer Schnittstelle zum Computeralgebra-System Sage.
- ConImp: Für Linux und DOS/Windows, kommandozeilenbasiert, beschränkt auf formale Kontexte mit 256 Gegenständen, jedoch mit erweiterten Optionen wie Eingabe von Hintergrund- und unvollständigem Wissen. Hintergrundwissen verändert dort – im Unterschied zum oben beschriebenen und in conexp-clj implementierten Ansatz – den Algorithmus nicht, sondern es werden vorgeschlagene Implikationen durch Folgern aus einer Menge von Hintergrund-Implikationen entschieden, nicht durch den Experten.
Literatur
- Bernhard Ganter, Rudolf Wille: Formale Begriffsanalyse; Springer, 1996, ISBN 3-540-60868-0
- Bernhard Ganter, Sergei Obiedkov: Conceptual Exploration; Springer, 2016, ISBN 978-3-662-49290-1
Weblinks
- Dresdener Seite zur Formalen Begriffsanalyse (englisch)
- Dort Vorlesungsfolien (PDF; 2,1 MB) als ausführliche Einführung zu FCA und Merkmalexploration.
Einzelnachweise
- Bernhard Ganter, Rudolf Wille: Formale Begriffsanalyse; Springer, 1996, ISBN 3-540-60868-0, Theorem 8, S. 85
- Bernhard Ganter: Finger Exercises in Formal Concept Analysis (PDF; 2,1 MB); Vorlesungsfolien, Dresden 2006, S. 85–87.
- Gerd Stumme, Attribute Exploration with Background Knowledge and Exceptions. In: H.H. Bock u. a., Data Analysis and Information Systems. Springer 1996, S. 457–469. Preprint (PDF; 219 kB)
- Bernhard Ganter: Contextual Attribute Logic of Many-Valued Attributes. In Bernhard Ganter, Gerd Stumme, Rudolf Wille (Hrsg.): Formal Concept Analysis. Foundations and Applications; Springer, 2005, ISBN 3-540-27891-5, S. 107. Online-Version
- Franz Baader and Barıs Sertkaya: Usability Issues in Description Logic Knowledge Base Completion. In S. Ferre and S. Rudolph (Hrsg.): Formal Concept Analysis: 7th International Conference, ICFCA 2009, LNAI 5548; Springer, Heidelberg 2009, p. 1–21.
- Johannes Wollbold: Attribute Exploration of Gene Regulatory Processes (PDF; 4,4 MB). Doktorarbeit, Universität Jena 2011.