Multidimensionale Skalierung
Die Multidimensionale Skalierung (auch Mehrdimensionale Skalierung, oder Ähnlichkeitsstrukturanalyse, abgekürzt: MDS) ist ein Bündel von Verfahren der multivariaten Statistik. Ihr formales Ziel ist es, die Objekte räumlich so anzuordnen, dass die Abstände (Distanzen) zwischen den Objekten im Raum möglichst exakt den erhobenen Un-/ Ähnlichkeiten entsprechen. Je weiter die Objekte voneinander entfernt sind, desto unähnlicher sind sie und je näher sie beieinander sind, desto ähnlicher sind sie. Es werden also Informationen über Paare von Objekten erhoben, um daraus metrische Informationen über die Objekte zu ermitteln.
Die Lösung der multidimensionalen Skalierung, die sogenannte Konfiguration, wird meist in zwei oder drei Dimensionen geschätzt, was die Interpretierbarkeit erleichtert. Prinzipiell kann die Konfiguration für Objekte in einem bis zu -dimensionalen Raum bestimmt werden. Neben der räumlichen Konfiguration von Objekten liefert die multidimensionale Skalierung eine Reihe von Kennziffern (z. B. Stress1, S-Stress, ALSCAL, Bestimmtheitsmaß usw.), welche die Güte der Konfiguration beurteilen.


Die multidimensionale Skalierung geht zurück auf den Psychologen Warren S. Torgerson (Veröffentlichungen 1952–1968). Die wichtigsten statistischen Verfahren sind die metrische bzw. die nicht metrische multidimensionale Skalierung nach Kruskal.[1]
Ein Anwendungsbeispiel für die multidimensionale Skalierung ist das Property Fitting im Marketing.
Verschiedene Verfahren der MDS
Bei den verschiedenen Verfahren der MDS kann allgemein zwischen solchen für quadratische Matrizen und solchen für rechteckige Matrizen unterschieden werden. Dabei können bei als matrixkonditional bezeichneten Daten maximal die Werte innerhalb einer Matrix miteinander verglichen werden und entsprechend bei zeilenkonditionalen Daten nur die Werte innerhalb einer Zeile.
Es können drei Modellkonstellationen unterschieden werden:
- einfache MDS: eine Matrix und eine Konfiguration (Es wird von einem allen Subjekten inhärenten Wahrnehmungsraum ausgegangen, was nicht durch das Modell geprüft wird.)
- wiederholte MDS: mehr als eine Matrix aber ebenfalls nur eine Konfiguration (Gleiche Hypothese wie bei der einfachen MDS, aber hier wird diese durch das Modell geprüft)
- INDSCAL: mehr als eine Matrix und mehr als eine Konfiguration, genauer werden jeder individuellen Matrix für jede Dimension Stauchungs- bzw. Streckungsfaktoren zugewiesen und auf eine allgemeine Konfiguration angewandt. Es wird von einem allen Subjekten inhärenten Wahrnehmungsraum ausgegangen, dessen Dimensionen aber individuell als unterschiedliche wichtig bewertet werden, was durch das Verfahren geprüft wird.
Zu den Verfahren für zeilenkonditionale Daten zählen:
- Ankerpunktmethode: ein Objekt dient als Referenzpunkt für alle anderen Objekte. Die Matrix ist dann zwar quadratisch, aber asymmetrisch und daher zeilenkonditional.
- Multidimensionale Entfaltung (MDU): nicht ein Objekt, sondern jedes Subjekt wird als Ankerpunkt interpretiert.
Metrische multidimensionale Skalierung
Ziel der metrischen multidimensionalen Skalierung ist es, Objekte mit Abständen im hoch dimensionalen Raum so in einem kleineren -dimensionalen Raum anzuordnen, dass die euklidischen Distanzen in diesem Raum möglichst genau den Distanzen gleichen. Diese Konfiguration lässt sich durch die Verwendung der euklidischen Metrik leicht interpretieren, da Distanzen zwischen den Objekten ihrer Entfernung per Luftlinie entsprechen.


Neben euklidischen Distanzmaßen sind auch die in Faktorenanalysen verwendeten Metriken gebräuchlich. In diskreten Modellen kommt unter anderem die Manhattan-Metrik zum Einsatz.
Sind als Startwerte anstatt Distanzen Ähnlichkeitsmaße zwischen Objekten gegeben, so lassen sich diese durch die Transformation


in Distanzen überführen.
Algorithmus
Das Verfahren zur multidimensionalen Skalierung lässt sich in 4 Schritten beschreiben:
- Definiere Matrix mit
- Definiere Matrix mit wobei den Durchschnitt der Zeile , den Durchschnitt der Spalte und den Durchschnitt aller Elemente von bezeichne.
- Bestimme die Eigenwerte und die zugehörigen Eigenvektoren der Matrix mit der Eigenschaft: .
- Die Koordinaten der zu skalierenden Datenpunkte im dimensionalen Raum ergeben sich dann aus den Eigenvektoren zu den größten Eigenwerten: .














Beispiel
Gegeben sind die Distanzen der schnellsten Autoverbindungen zwischen verschiedenen Städten und gesucht werden die Koordinaten der Städte.
| Berlin | Frankfurt | Hamburg | Köln | München | |
|---|---|---|---|---|---|
| Berlin | 0 | 548 | 289 | 576 | 586 |
| Frankfurt | 548 | 0 | 493 | 195 | 392 |
| Hamburg | 289 | 493 | 0 | 427 | 776 |
| Köln | 576 | 195 | 427 | 0 | 577 |
| München | 586 | 392 | 776 | 577 | 0 |
Die metrische multidimensionale Skalierung für eine Konfiguration in zwei Dimensionen mit einer Statistiksoftware ergibt
| Stadt | X | Y | Grafische Konfiguration |
|---|---|---|---|
| Berlin | 0,8585 | −1,1679 | 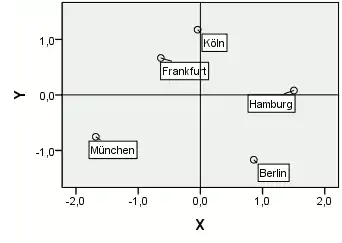 |
| Frankfurt | −0,6363 | 0,6660 | |
| Hamburg | 1,5036 | 0,0800 | |
| Köln | −0,0438 | 1,1760 | |
| München | −1,6821 | −0,7542 |
Die gefundene Konfiguration ist eindeutig, bis auf Rotation und Skalierung:
- Jede rotierte Lösung liefert natürlich die gleichen (euklidischen) Distanzen zwischen den Städten und damit sind diese Lösungen gleichwertig.
- Aufgrund der Standardisierung im Algorithmus liefert eine gleichmäßige Vervielfachung des Abstandes aller Städte vom Nullpunkt die gleichen Koordinaten für die Städte.

Nicht-metrische multidimensionale Skalierung
Die nicht-metrische multidimensionale Skalierung will die metrische multidimensionale Skalierung in zwei Aspekten erweitern:
- keine Angabe einer expliziten Funktion zur Umwandlung von (Un-)Ähnlichkeiten in Distanzen und
- die Nutzung nicht-euklidischer Geometrien zur Auffindung von Konfigurationen.
Hängen die Unähnlichkeiten mit den Distanzen über zusammen, so muss diese Funktion schwach monoton sein: Gilt , dann muss gelten .





Bringt man daher die Paare von Unähnlichkeiten in eine Rangfolge

so ergibt sich die Monotonie-Bedingung
- .

Shepard-Kruskal Algorithmus
Der Shepard-Kruskal Algorithmus ermittelt die Konfiguration iterativ:
- Initialisierung : Wähle gewünschte Dimensionalität und ordne Objekte zufällig im Zielraum an. (Für lassen sich die Ergebnisse oft eingänglich darstellen.) Berechne die Distanzen zwischen allen Objekten und .
- Schritt : Schätze Disparitäten der Objekte und unter Verwendung ihrer Distanz . Hierfür kann der Pool-Adjacent Violators Algorithmus (siehe unten) benutzt werden.
- Abbruchbedingung: Sobald eines der ausgewählten Abbruchkriterien (siehe folgenden Abschnitt) für den iterativen Prozess erreicht ist, endet der iterative Prozess mit der gefundenen Konfiguration, die (eventuell nur lokal) optimal ist. Andernfalls fahre mit Punkt 4 fort.
- Anpassung der Positionen an die Disparitäten: Berechne die neuen Koordinatenwerte für alle Objektpaare und (siehe unten), z. B. ähnlich einem Gradientenverfahren. Ermittle die Distanzen für die neuen Positionen und fahre mit Punkt 2 fort.










Pool-Adjacent Violators Algorithmus
- Wenn die Monotoniebedingung zwischen zwei benachbarten Punkten nicht verletzt ist, verwenden wir die jeweiligen Distanz als Disparität, also .
- Wenn die Monotonie-Bedingung zwischen zwei () oder mehr () benachbarten Punkten verletzt ist, so verwenden wir den Mittelwert der entsprechenden Distanzen als Disparitäten, also .[2]




Welche Transformationen bei der Berechnung der Disparitäten zulässig sind, hängt vom Skalenniveau der Rohdaten ab. Die Distanzen im Wahrnehmungsraum können aber durchaus ein anderes Skalenniveau annehmen. Inwieweit eine Anhebung des Skalenniveaus zulässig ist, wird mittels des Verdichtungsquotienten Q (Zahl der Ähnlichkeiten/(Zahl der Dimensionen*Zahl der Objekte)) beurteilt. Bei der „einfachen“ MDS liegen die Rohdaten schon in aggregierter Form vor, stellen also meist die Mittelwerte über die Antworten der Befragten dar.
Berechnung der neuen Positionen
Die neue Position wird berechnet als
- .

Dabei ist die Position von Objekt zum Zeitpunkt und ein Gewichtungsfaktor (nicht zu groß wählen, da sich der Stress-Wert auch verschlechtern kann – in der Regel 0,2).


Wenn nun zwei Objekte im Verhältnis zu ihrer Ähnlichkeit zu weit auseinanderliegen ( ist größer 1, wodurch der Ausdruck in der Klammer negativ wird), werden sie aufeinander zu geschoben (die Richtung wird dabei durch die Differenz in der zweiten Klammer bestimmt). Zwei eher unähnliche Objekte, die zu nahe beieinander liegen, bewegt man voneinander weg. Dadurch wird der Stress-Wert in der Regel gesenkt und die Iteration wird mit Schritt 2. fortgeführt, wodurch sich der Stress-Wert in der Regel erneut senkt.

Beispiel
Basierend auf dem obigen Beispiel können wir eine Rangfolge der Distanzen erstellen und die Monotoniebedingung aufstellen:
| Distanz: | < | < | < | < | < | < | < | < | < | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Monotoniebedingung: | < | < | < | < | < | < | < | < | < |




















Es wurde zu Beginn eine zufällige Konfiguration gewählt:
| Position | Distanz zu | ||||||
|---|---|---|---|---|---|---|---|
| Ort | X | Y | Berlin | Frankfurt | Hamburg | Köln | München |
| Berlin | 0,9961 | −1,5759 | 0 | ||||
| Frankfurt | −1,1453 | 0,7840 | 3,1866 | 0 | |||
| Hamburg | −0,7835 | 0,9408 | 3,0824 | 0,3942 | 0 | ||
| Köln | −0,1025 | −0,0208 | 1,9041 | 1,3172 | 1,1783 | 0 | |
| München | 1,0352 | −0,1281 | 1,4483 | 2,3635 | 2,1096 | 1,1428 | 0 |
daraus ergibt sich:
| Monotoniebed.: | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PAV | |||||||||||||||||||





















Aus den berechneten euklidischen Distanzen ergibt sich, dass die Monotoniebedingung in zwei Bereichen verletzt ist:
- und
- .


Die Disparitäten werden daher als Mittelwerte (1,7546 bzw. 1,9447) der entsprechenden Bereiche berechnet. Mit den Disparitäten können nun die Punktpositionen verschoben werden. Dieses Verfahren wird iteriert und führt zur nebenstehenden Lösung.
Abbruch- bzw. Gütekriterien
Ziel des Verfahrens ist eine optimale Anpassung der MDS-Lösung an die Rohdaten und somit ein möglichst geringer STRESS- oder Energiewert bzw. ein möglichst großes Bestimmtheitsmaß. Diese Werte sind als Unterschied zwischen Disparität und Distanz zu verstehen. Verändern sich die Werte nicht mehr oder nur geringfügig, wird das Iterationsverfahren abgebrochen.
STRESS-Maße
Der STRESS-Wert (STRESS für STandardized REsidual Sum of Squares, deutsch: standardisierte Residuenquadratsumme) berechnet sich (nach Kruskal) als Wurzel aus der Summe der Abweichungsquadrate der Disparitäten von den Distanzen, geteilt durch die Summe der quadrierten Distanzen. Damit ist STRESS ein normiertes Varianzmaß:
| Anpassungsgüte | STRESS 1 | STRESS 2 |
|---|---|---|
| gering | 0,2 | 0,4 |
| ausreichend | 0,1 | 0,2 |
| gut | 0,05 | 0,1 |
| ausgezeichnet | 0,025 | 0,05 |
| perfekt | 0 | 0 |

Ein alternatives STRESS Maß ist

mit der Mittelwert aller Distanzen.

Prinzipiell gibt es keine exakten Vorgaben dafür, welcher STRESS-Wert noch akzeptabel ist und welchen man als „gut“ bezeichnen kann. „Um überhaupt eine Norm zu haben, hat man die ‚nullste aller Nullhypothesen’ untersucht und tausende von Zufallsdaten per MDS skaliert und dabei registriert, welche Stress-Werte sich ergeben“ (vgl. BORG/ STAUFENBIEL 1989). Kruskal[1] hat Anhaltswerte für den STRESS-Wert erstellt, an denen man sich orientieren kann.
Bestimmtheitsmaß
Neben den einfachen Kostenkriterien STRESS wird ein alternatives Maß als Gütekriterium für die Anpassung der Konfiguration an die Rohdaten verwendet. Das Bestimmtheitsmaß ist die quadrierte Korrelation der Distanzen mit den Disparitäten und als Pegel der linearen Anpassung der Disparitäten an die Distanzen zu sehen. In der Praxis gelten Werte, die größer sind als 0,9 für das Bestimmtheitsmaß als akzeptabel.


Software
In Statistikprogrammen, wie SPSS, kann die MDS automatisch durchgeführt werden. In R führt die Funktion cmdscale eine MDS durch. Ebenso verhält es sich mit Matlab, welches MDS durch die Funktion mdscale bereitstellt.
Literatur
- Thomas A. Runkler: Data Mining Methoden und Algorithmen intelligenter Datenanalyse. Vieweg+Teubner, 2010, S. 41–47.
- W. S. Torgerson: Theory & Methods of Scaling. Wiley, New York 1958.
- I. Borg, Th. Staufenbiel: Theorien und Methoden der Skalierung. Huber, Bern 2007.
- Backhaus, Erichson, Plinke, Weiber: Multivariate Analysemethoden. Springer Verlag, Berlin 2000
- R. Mathar: Multidimensionale Skalierung. Teubner, Stuttgart 1997
- I. Borg, P. Groenen: Modern Multidimensional Scaling: Theory and Applications. Springer, New York 2005.
Einzelnachweise
- J. B. Kruskal. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. In: Psychometrika, 29(1), 1964, S. 1–27, doi:10.1007/BF02289565
- Kappelhoff: Multidimensionale Skalierung – Beispiel zur Datenanalyse. (PDF; 404 kB) Lehrstuhl für empirische Wirtschafts- und Sozialforschung, 2001
- Wojciech Basalaj: Proximity Visualization of Abstract Data. (PDF; 7,3 MB) 2001; abgerufen am 19. Juni 2013