Maschinelles Lernen
Maschinelles Lernen (ML) ist ein Fachgebiet, das statistische Algorithmen entwickelt und untersucht. Diese Algorithmen können aus Daten, die in maschinenlesbarer Form vorliegen und Informationen über Beobachtungen oder Erfahrungen enthalten, ein bestimmtes Verhalten lernen. Das Verhalten wird nicht explizit programmiert, sondern von den Algorithmen direkt aus den Daten gelernt. Das Lernen aus Daten bezeichnet man in der mathematischen Statistik auch als Statistisches Lernen.[1]
Aus dem weiten Spektrum möglicher Anwendungen seien hier genannt: Spamfilter, automatisierte Diagnoseverfahren, Erkennung von Kreditkartenbetrug, Aktienmarktanalysen, Klassifikation von Nukleotidsequenzen, Sprach- und Texterkennung sowie AlphaGo.
Allgemein formuliert ist das Ziel beim maschinellen Lernen, dass ein Algorithmus aus Daten eine Funktion lernt, die anschließend auch für nicht gelernte Dateneingaben eine korrekte Ausgabe erzeugt. Damit der Algorithmus lernen kann, was „korrekt“ ist, werden beim überwachten Lernen in den Daten, die zum Lernen verwendet werden, bereits korrekte Ausgabewerte zur Verfügung gestellt. Typische Anwendungsbeispiele sind Klassifikation und Regression. Beim bestärkenden Lernen lernen die Algorithmen die geforderten Ausgabewerte aus kontinuierlichen Rückmeldungen. Ein bekanntes Anwendungsbeispiel ist AlphaGo. Beim unüberwachten Lernen durchsuchen die Algorithmen die Daten ohne vorgegebene Ausgabewerte oder Rückmeldungen beispielsweise nach Kriterien für die Einteilung in unterschiedliche Cluster oder nach korrelierenden Merkmalen, die zusammengefasst werden können, um die Daten zu vereinfachen. Da es keine Vorgaben gibt, können die Algorithmen unterschiedliche Lösungen vorschlagen, die anschließend zu bewerten sind. Ein typisches Anwendungsbeispiel ist die Vorbereitung von Datensätzen für das überwachte Lernen.[2]
In der Theorie des computergestützten Lernens bietet das Probably Approximately Correct Learning einen Rahmen für die Beschreibung des ML.
Verwandte Fachgebiete
Das maschinelle Lernen ist ein Teilgebiet des Fachgebietes „Künstliche Intelligenz“, auch KI genannt. Ursprünglich gab es nur das Fachgebiet „Künstliche Intelligenz“. Etwa ab 1980 entwickelten sich die Ziele und Methoden innerhalb der KI in verschiedene Richtungen. Die meisten Forscher untersuchten vorrangig, welche Rolle Wissen bei der Entstehung von Intelligenz spielt. Parallel untersuchte eine kleine Gruppe von Forschern, ob sich die Leistung von Computern bei Vorhersagen dadurch verbessern lässt, dass sie Wissen aus Daten lernen, die Informationen zu Erfahrungen aus dem Problemfeld enthalten. Der Bereich KI zeigte zu dieser Zeit nur wenig Interesse am Lernen aus Daten. Deshalb gründeten diese Forscher den neuen Bereich ML. Das Ziel von ML ist nicht mehr, künstliche Intelligenz zu erreichen, sondern praktische Probleme zu lösen.[3]
ML und Statistik verwenden sehr ähnliche Methoden. Die beiden Fachgebiete unterscheiden sich allerdings in ihrem Hauptziel. Viele der eingesetzten Methoden können sowohl angewendet werden, um Schlussfolgerungen zu ziehen als auch, um Vorhersagen zu treffen. Die Statistik benutzt Daten von sorgfältig ausgewählten Stichproben, um daraus Rückschlüsse zu Eigenschaften einer zu untersuchenden Gesamtmenge zu ziehen. Die Methoden in der Statistik legen deshalb den Schwerpunkt darauf, statistische Modelle zu erstellen und diese genau an die gegebene Problemstellung anzupassen. Damit kann man berechnen, mit welcher Wahrscheinlichkeit gefundene Zusammenhänge echt sind und nicht durch Störungen erklärt werden können. Die Methoden im ML hingegen verarbeiten große Datenmengen und lernen daraus mit allgemein formulierten Algorithmen Zusammenhänge, die verallgemeinert und für Vorhersagen benutzt werden. Auch wenn ML für ein gegebenes Problem überzeugende Vorhersageergebnisse liefert, kann man daraus möglicherweise keine Regeln ableiten, solange das explizite Modell fehlt.[4]
ML ist ein wichtiger Baustein des interdisziplinären Wissenschaftsfeldes „Data Science“.[5] Dieser Bereich befasst sich mit der Extraktion von Erkenntnissen, Mustern und Schlüssen sowohl aus strukturierten als auch unstrukturierten Daten.
ML überschneidet sich teilweise mit „Knowledge Discovery in Databases“ und „Data-Mining“, bei denen es jedoch vorwiegend um das Finden von neuen Mustern und Gesetzmäßigkeiten geht. Viele Algorithmen können für beide Zwecke verwendet werden. Methoden der „Knowledge Discovery in Databases“ können genutzt werden, um Lerndaten für ML zu produzieren oder vorzuverarbeiten. Im Gegenzug dazu finden Algorithmen aus dem ML beim Data-Mining Anwendung.[2]:16–18
ML umfasst alle Methoden, mit denen Computer Wissen aus Daten lernen. Ein Teilgebiet von ML sind „Künstliche Neuronale Netze“. Ein Teilgebiet innerhalb der künstlichen neuronalen Netze ist wiederum „Deep Learning“. Mit Hilfe von künstlichen neuronalen Netzen und Deep Learning konnte die Leistung gegenüber früheren Ansätzen beispielsweise in den Bereichen natürliche Sprachverarbeitung und Spracherkennung deutlich gesteigert werden.[5]
Die Mathematische Optimierung ist eine mathematische Grundlage des ML. Die bestmögliche Anpassung eines Modells an die Trainingsdaten ist ein Optimierungsproblem. Beispielsweise wenden einige Lernalgorithmen das Gradientenverfahren an, um Modellparameter zu optimieren.
Methoden
Die Methoden von ML können nach verschiedenen Kriterien in Kategorien eingeteilt werden.
Repräsentation des Wissens
Das maschinelle Lernen verarbeitet Daten, die Informationen enthalten, und leitet daraus mit induktiven Methoden Wissen ab. Ob das abgeleitete Wissen korrekt ist, hängt von der Anzahl und der Repräsentativität der zur Verfügung gestellten Datenpunkte ab. Viele Anwendungsfälle erfordern, dass die Regeln, die das Modell aus Daten gelernt hat und im Einsatz verwendet, von Menschen nachvollzogen und überprüft werden können.[6]
Zu Beginn hatte ML das Ziel, automatisch Expertensysteme zu erzeugen und nachzubilden, wie Menschen lernen. Der Schwerpunkt lag auf symbolischen Ansätzen. Dabei wird das Wissen in Form von Regeln oder logischen Formeln repräsentiert. Bei symbolischen Ansätzen können Menschen die Zusammenhänge und Muster, die das System für seine Vorhersagen benutzt, leicht erkennen und überprüfen.
Später änderte ML sein Ziel dahingehend, dass alle Methoden untersucht werden sollten, die die Leistung steigern können. Dazu gehören auch nicht-symbolische Ansätze, beispielsweise künstliche neuronale Netze, die zwar ein berechenbares Verhalten lernen, das erworbene Wissen aber implizit repräsentieren.
Bei nicht-symbolischen Ansätzen können Menschen nicht erkennen, welche Zusammenhänge und Muster das System für eine Vorhersage benutzt. Dadurch kann das Erstellen eines geeigneten Trainingsdatensatzes sehr schwierig werden. Man muss verhindern, dass die Daten Muster aufweisen, die das Modell nicht zur Entscheidung heranziehen soll. Wenn es beispielsweise einen Zusammenhang gibt zwischen der Helligkeit von Trainingsbildern und den tatsächlich gesuchten Eigenschaften dieser Bilder, dann lernt ein künstliches neuronales Netz unter Umständen, die Bilder nur aufgrund ihrer Helligkeit zu klassifizieren. Dann würde das Netz alle neuen Bilder mit bestimmten Eigenschaften falsch klassifizieren. Der Aufwand dafür, solche Fehler zu erkennen, kann sehr hoch sein.[3]
Bei den symbolischen Ansätzen werden aussagenlogische und prädikatenlogische Systeme unterschieden. In der Aussagenlogik hat jede Aussage einen von genau zwei Wahrheitswerten. Der Wahrheitswert jeder zusammengesetzten Aussage ist eindeutig durch die Wahrheitswerte ihrer Teilaussagen bestimmt. Ein Beispiel für ein solches System ist ein Entscheidungsbaum, Beispiele für entsprechende Algorithmen sind ID3 und sein Nachfolger C4.5. Die Prädikatenlogik ist eine Erweiterung der Aussagenlogik. Sie spielt in der Konzeption und Programmierung von Expertensystemen eine Rolle, siehe auch induktive logische Programmierung.
Trainingsüberwachung
Beim Training verarbeiten die Algorithmen Trainingsdatensätze. Während des Trainings benötigen sie Rückmeldungen dazu, welche Ausgaben für einzelne Datenpunkte erwartet werden. Man unterscheidet zwischen drei Hauptgruppen der Trainingsüberwachung:[7] überwachtes Lernen (englisch supervised learning), unüberwachtes Lernen (englisch unsupervised learning) und bestärkendes Lernen (engl. reinforcement learning).
Überwachtes Lernen
Beim überwachten Lernen wird ein Lernalgorithmus mit Datensätzen trainiert und validiert, die für jede Eingabe einen passenden Ausgabewert enthalten. Man bezeichnet solche Datensätze als markiert oder gelabelt. Die Methode richtet sich also nach einer im Vorhinein festgelegten zu lernenden Ausgabe, deren Ergebnisse bekannt sind. Die Ergebnisse des Lernprozesses können mit den bekannten, richtigen Ergebnissen verglichen, also „überwacht“, werden.
Die Algorithmen bauen zunächst in einer Lernphase aus einem Trainingsdatensatz ein statistisches Modell auf. Das Schließen von Daten auf (hypothetische) Modelle wird als statistische Inferenz bezeichnet. Nach der Lernphase wird die Qualität des erzeugten Modells mit einem Testdatensatz überprüft, der beim Training nicht verwendet wurde. Das Ziel ist, dass das Modell auch für völlig neue Daten das geforderte Verhalten zeigt. Dazu muss sich das Modell gut an die Trainingsdaten anpassen, gleichzeitig muss eine Überanpassung vermieden werden.[8][9]
Es lassen sich noch einige Unterkategorien für überwachtes Lernen identifizieren, die in der Literatur häufiger erwähnt werden:
- Teilüberwachtes Lernen (englisch semi-supervised learning): Der Datensatz enthält nur für einen Teil der Eingaben die dazugehörigen Ausgaben.[10] Nun werden in der Regel zwei Algorithmen kombiniert. Im ersten Schritt teilt ein Algorithmus für unüberwachtes Lernen die Eingaben in Cluster auf und labelt anschließend alle Eingaben eines Clusters mit dem Label anderer Datenpunkte aus demselben Cluster. Danach wird ein Algorithmus für überwachtes Lernen eingesetzt.[11]
- Aktives Lernen (englisch active learning): Der Algorithmus hat die Möglichkeit, für einen Teil der Eingaben die korrekten Ausgaben zu erfragen. Dabei muss der Algorithmus die Fragen bestimmen, welche einen hohen Informationsgewinn versprechen, um die Anzahl der Fragen möglichst klein zu halten.[12]
- Selbstüberwachtes Lernen (englisch self-supervised learning): Diese Methode kann wie das teilüberwachte Lernen in zwei Schritte aufgeteilt werden. Im ersten Schritt erstellt ein Algorithmus aus einem völlig ungelabelten Datensatz einen neuen Datensatz mit Pseudolabeln. Dieser Schritt gehört eigentlich zum unüberwachten Lernen. Danach wird ein Algorithmus für überwachtes Lernen eingesetzt.[11]:43-44
Unüberwachtes Lernen
Der Algorithmus erzeugt für eine gegebene Menge von Eingaben ein statistisches Modell, das die Eingaben beschreibt und erkannte Kategorien und Zusammenhänge enthält und somit Vorhersagen ermöglicht. Clustering-Verfahren teilen Daten in mehrere Kategorien ein, die sich durch charakteristische Muster voneinander unterscheiden. Diese Verfahren erstellen selbständig Klassifikatoren. Ein wichtiger Algorithmus in diesem Zusammenhang ist der EM-Algorithmus, der iterativ die Parameter eines Modells so festlegt, dass es die gesehenen Daten optimal erklärt. Er legt dabei das Vorhandensein nicht beobachtbarer Kategorien zugrunde und schätzt abwechselnd die Zugehörigkeit der Daten zu einer der Kategorien und die Parameter, die die Kategorien ausmachen. Eine Anwendung des EM-Algorithmus findet sich beispielsweise in den Hidden Markov Models (HMMs). Andere Methoden des unüberwachten Lernens, z. B. die Hauptkomponentenanalyse, zielen darauf ab, die beobachteten Daten in eine einfachere Repräsentation zu übersetzen, die sie trotz drastisch reduzierter Information möglichst genau wiedergibt.
Bestärkendes Lernen
Beim bestärkenden Lernen entwickeln Agenten selbständig eine Strategie, um erhaltene Belohnungen zu maximieren.[13][14] Aufgrund seiner Allgemeingültigkeit wird dieses Gebiet auch in vielen anderen Disziplinen untersucht, z. B. in der Spieltheorie, der Kontrolltheorie, dem Operations Research, der Informationstheorie, der simulationsbasierten Optimierung, den Multiagentensystemen, der Schwarmintelligenz, der Statistik und den genetischen Algorithmen. Beim maschinellen Lernen wird die Umgebung normalerweise als Markov-Entscheidungsprozess (MDP) dargestellt. Viele Algorithmen des Verstärkungslernens verwenden Techniken der dynamischen Programmierung.[15] Verstärkungslernalgorithmen setzen keine Kenntnis eines exakten mathematischen Modells des MDP voraus und werden eingesetzt, wenn exakte Modelle nicht durchführbar sind. Verstärkungslernalgorithmen werden in autonomen Fahrzeugen oder beim Lernen eines Spiels gegen einen menschlichen Gegner eingesetzt.
Batch- und Online-Learning
Beim Batch-Learning, auch Offline-Learning genannt, werden alle Eingabe/Ausgabe-Paare auf einmal eingelesen. Das System kann in dieser Zeit nicht benutzt werden und ist in der Regel Offline. Nach dem Training kann das System nicht durch neue Daten verbessert werden. Wenn neue Daten dazu gelernt werden sollen, dann ist ein vollständiger neuer Trainingslauf mit allen Daten, alten und neuen, erforderlich.
Beim Online-Learning, auch inkrementelles Lernen genannt, wird das System inkrementell mit kleineren Datensätzen trainiert. Das Verfahren eignet sich gut für Systeme, die sich schnell an Veränderungen anpassen müssen. Dabei müssen neue Daten genau so hochwertig sein wie alte. Wenn neue Daten beispielsweise ungeprüft von einem defekten Sensor übernommen werden, besteht die Gefahr, dass das Modell mit der Zeit schlechter wird.[16][11]:46-49
Lernen von Instanzen oder Modellen
Beim ML geht es oft darum, Vorhersagen zu treffen. Dazu muss ein System von den gelernten Daten auf unbekannte Daten verallgemeinern.
Eine einfache Methode besteht darin, dass das System direkt die Merkmale von neuen Datenpunkten mit denen der gelernten Datenpunkte vergleicht und ihre Ähnlichkeit vergleicht. Man bezeichnet das als instanzbasiertes Lernen. In der Trainingsphase lernt das System nur die Trainingsdaten. Danach berechnet es bei jeder Anfrage die Ähnlichkeit von neuen Datenpunkten mit gelernten und erzeugt aus dem Ähnlichkeitsmaß eine Antwort. Ein Beispiel ist die Nächste-Nachbarn-Klassifikation.
Die andere Methode besteht darin, dass das System in der Trainingsphase ein Modell entwickelt und seine Parameter so an die Trainingsdaten anpasst, dass das Modell korrekte Verallgemeinerungen oder Vorhersagen machen kann. Man bezeichnet das als modellbasiertes Lernen.[11]:49-50
Modelle
Beim maschinellen Lernen wird oft ein Modell erstellt, das mit einem Trainingsdatensatz trainiert wird und danach weitere Daten verarbeiten kann, um Vorhersagen zu treffen. Es gibt viele Arten von Modellen, die untersucht wurden und in solchen Systemen verwendet werden.
Lineare Regression
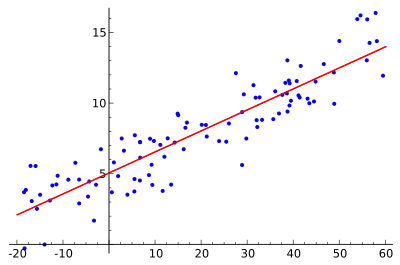
Die lineare Regression ist ein statistisches Verfahren, mit dem versucht wird, eine beobachtete abhängige Variable durch eine oder mehrere unabhängige Variablen zu erklären. Bei der linearen Regression wird dabei ein lineares Modell angenommen. Bei der einfachen linearen Regression wird mithilfe zweier Parameter eine Gerade (Regressionsgerade) so durch eine Punktwolke gelegt, dass der lineare Zusammenhang zwischen und möglichst gut beschrieben wird.


Um eine möglichst genaue Vorhersage für die abhängige Variable zu erhalten, wird eine sogenannte „Kostenfunktion“ aufgestellt. Diese Funktion beschreibt die mittlere quadratische Abweichung, die dadurch entsteht, dass die Regressionsgerade die zu erklärende Variable nur approximiert und nicht genau darstellt. Der Lernalgorithmus minimiert diese Kostenfunktion.
k-Means-Algorithmus

Der k-Means-Algorithmus ist ein Verfahren zur Vektorquantisierung, das auch zur Clusteranalyse verwendet wird. Dabei wird aus einer Menge von ähnlichen Objekten eine vorher bekannte Anzahl von k Gruppen gebildet. Der Algorithmus ist eine der am häufigsten verwendeten Techniken zur Gruppierung von Objekten, da er schnell die Zentren der Cluster findet. Dabei bevorzugt der Algorithmus Gruppen mit geringer Varianz und ähnlicher Größe.
In der Regel wird ein approximativer Algorithmus verwendet, der mit zufälligen Mittelwerten aus dem Trainigsdatensatz beginnt und sich danach in mehreren Schritten einer guten Clusteraufteilung annähert. Da die Problemstellung von k abhängig ist, muss dieser Parameter vom Benutzer festgelegt werden.
Support Vector Machines

Eine Support Vector Machine dient als Klassifikator und Regressor. Eine Support Vector Machine unterteilt eine Menge von Objekten so in Klassen, dass um die Klassengrenzen herum ein möglichst breiter Bereich frei von Objekten bleibt; sie ist ein sogenannter Large Margin Classifier (dt. „Breiter-Rand-Klassifikator“).
Jedes Objekt wird durch einen Vektor in einem Vektorraum repräsentiert. Aufgabe der Support Vector Machine ist es, in diesen Raum eine Hyperebene einzupassen, die als Trennfläche fungiert und die Trainingsobjekte in zwei Klassen teilt. Der Abstand derjenigen Vektoren, die der Hyperebene am nächsten liegen, wird dabei maximiert. Dieser breite, leere Rand soll später dafür sorgen, dass auch Objekte, die nicht genau den Trainingsobjekten entsprechen, möglichst zuverlässig klassifiziert werden.

Eine saubere Trennung mit einer Hyperebene ist nur dann möglich ist, wenn die Objekte linear trennbar sind. Diese Bedingung ist für reale Trainingsobjektmengen im Allgemeinen nicht erfüllt. Support Vector Machines überführen beim Training den Vektorraum und damit auch die darin befindlichen Trainingsvektoren in einen höherdimensionalen Raum, um eine nichtlineare Klassengrenze einzuziehen. In einem Raum mit genügend hoher Dimensionsanzahl – im Zweifelsfall unendlich – wird auch die verschachteltste Vektormenge linear trennbar.
Die Hochtransformation ist enorm rechenlastig und die Darstellung der Trennfläche im niedrigdimensionalen Raum im Allgemeinen unwahrscheinlich komplex und damit praktisch unbrauchbar. An dieser Stelle setzt der sogenannte Kernel-Trick an. Verwendet man zur Beschreibung der Trennfläche geeignete Kernelfunktionen, die im Hochdimensionalen die Hyperebene beschreiben und trotzdem im Niedrigdimensionalen „gutartig“ bleiben, so ist es möglich, die Hin- und Rücktransformation umzusetzen, ohne sie tatsächlich rechnerisch ausführen zu müssen.
Entscheidungsbäume

Beim Lernen von Entscheidungsbäumen wird ein Entscheidungsbaum als Modell verwendet, um Schlussfolgerungen aus den Beobachtungen zu ziehen, die im Trainingsdatensatz enthalten sind. Gelernte Regeln werden durch Knoten und Zweige des Baums repräsentiert und Schlussfolgerungen durch seine Blätter. Ein Modell mit diskreten Ausgabewerten (in der Regel ganzen Zahlen) nennt man Klassifizierungsbaum, dabei repräsentieren die Blattknoten die Klassen und die Zweige UND-Verknüpfungen der Merkmale, die zu der Klasse führen. Ein Modell mit kontinuierlichen Ausgabewerten (in der Regel reellen Zahlen) nennt man Regressionsbaum. Der Algorithmus wählt beim Training diejenige Reihenfolge für die Abfrage der Merkmale, bei der das Modell bei jeder Verzweigung möglichst viel Information erhält. Nach dem Training kann man das Modell auch dazu verwenden, explizit und graphisch die Regeln darzustellen, die zu einer Entscheidung führen.[2]:129-149
Der im Bild dargestellte Binärbaum benötigt als Eingabe einen Vektor mit den Merkmalen eines Apfelbaumes. Ein Apfelbaum kann beispielsweise die Merkmale alt, natürliche Sorte und reichhaltiger Boden besitzen. Beginnend mit dem Wurzelknoten werden nun die Entscheidungsregeln des Baumes auf den Eingabevektor angewendet. Gelangt man nach einer Folge ausgewerteter Regeln an ein Blatt, erhält man die Antwort auf die ursprüngliche Frage.
Random Forests

Ein Random Forest besteht aus mehreren unkorrelierten Entscheidungsbäumen. Ein Random Forest mittelt über mehrere Entscheidungsbäume, die auf verschiedenen Teilen desselben Trainingsdatensatzes trainiert wurden. Eine große Anzahl unkorrelierter Bäume macht genauere Vorhersagen möglich als ein einzelner Entscheidungsbaum. Dadurch wird in der Regel die Leistung des endgültigen Modells erheblich gesteigert.
Künstliche Neuronale Netze

Künstliche neuronale Netze (KNN) sind Modelle, deren Struktur von biologischen neuronalen Netzen, aus denen Tiergehirne bestehen, inspiriert wurde. Solche Modelle können aus komplexen und scheinbar zusammenhanglosen Informationen lernen. Einige erfolgreiche Anwendungen sind Bilderkennung und Spracherkennung.
Ein KNN wird von Einheiten oder Knoten gebildet, die miteinander verbunden sind. Die Knoten sind künstliche Neuronen. Ein künstliches Neuron empfängt Signale von verbundenen Neuronen und verarbeitet sie mit einer sogenannten Aktivierungsfunktion. Zusätzlich hat jede Verbindung ein Gewicht, das den Einfluss erhöht oder reduziert, den das entsprechende Signal auf die Aktivierungsfunktion hat. Eine verbreitete Form der Aktivierungsfunktion berechnet die Summe aller gewichteten Eingangssignale und legt sie als Signal auf alle Ausgänge, wenn sie einen bestimmten Schwellenwert überschreitet. Wenn die Summe unter dem Schwellenwert liegt, erzeugt diese Form der Aktivierungsfunktion kein Ausgangssignal. Zu Beginn stehen alle Schwellenwerte und Gewichte auf Zufallswerten. Während des Trainings werden sie an die Traingsdaten angepasst.
In der Regel werden die Neuronen in Schichten zusammengefasst. Die Signale wandern von der ersten Schicht (der Eingabeschicht) zur letzten Schicht (der Ausgabeschicht) und durchlaufen dabei möglicherweise mehrere Zwischenschichten (versteckte Schichten). Ein Netz wird als tiefes neuronales Netz bezeichnet, wenn es mindestens 2 versteckte Schichten hat. Darauf bezieht sich auch der Begriff Deep Learning. Jede Schicht kann die Signale an ihren Eingängen unterschiedlich transformieren.[17]
Bekannte Beispiele für Architekturen, die KNN einsetzen, sind rekurrente neuronale Netze (RNN) für die Verarbeitung von Sequenzen, convolutional neural networks (CNN) für die Verarbeitung von Bild- oder Audiodaten und generative vortrainierte Transformer (GPT) für Sprachmodelle.
Generative Adversarial Networks

Generative Adversarial Networks (GAN) ist die Bezeichnung für eine Klasse von maschinellen Lernverfahren, die KNN im Kontext von generativem Lernen bzw. unüberwachtem Lernen trainieren. Ein GAN besteht aus zwei KNN, die ein Nullsummenspiel durchführen. Das Modell lernt aus einem Trainingsdatensatz, neue Daten zu erzeugen, deren Eigenschaften denen der Trainingsdaten gleichen. Beispielsweise kann ein GAN, das mit Fotografien trainiert wurde, neue Fotografien erzeugen, die für menschliche Betrachter zumindest oberflächlich authentisch aussehen und viele realistische Merkmale aufweisen. Obwohl sie ursprünglich als generatives Modell für unüberwachtes Lernen vorgeschlagen wurden, haben sich GAN auch für teilüberwachtes Lernen, überwachtes Lernen und bestärkendes Lernen als nützlich erwiesen.
GAN sind ein wichtiger Baustein für die Entwicklung einer generativen künstlichen Intelligenz. Das ist die Bezeichnung für eine künstliche Intelligenz, die in der Lage ist, neue Texte, Bilder, Videos oder andere Daten zu erzeugen, in der Regel als Antwort auf Benutzeranfragen.
Automatisiertes Maschinelles Lernen
Das Ziel des automatisierten maschinellen Lernens besteht darin, möglichst viele Arbeitsschritte zu automatisieren. Dazu gehören die Auswahl eines geeigneten Modells und die Anpassung seiner Hyperparameter.[11]:383
Siehe auch
Literatur
- Andreas C. Müller, Sarah Guido: Einführung in Machine Learning mit Python. O’Reilly-Verlag, Heidelberg 2017, ISBN 978-3-96009-049-6.
- Christopher M. Bishop: Pattern Recognition and Machine Learning. Information Science and Statistics. Springer-Verlag, Berlin 2008, ISBN 978-0-387-31073-2.
- David J. C. MacKay: Information Theory, Inference and Learning Algorithms. Cambridge University Press, Cambridge 2003, ISBN 0-521-64298-1 (Online).
- Trevor Hastie, Robert Tibshirani, Jerome Friedman: The Elements of Statistical Learning. Data Mining, Inference, and Prediction. 2. Auflage. Springer-Verlag, 2008, ISBN 978-0-387-84857-0 (stanford.edu [PDF]).
- Thomas Mitchell: Machine Learning. Mcgraw-Hill, London 1997, ISBN 0-07-115467-1.
- D. Michie, D. J. Spiegelhalter: Machine Learning, Neural and Statistical Classification. In: Ellis Horwood Series in Artificial Intelligence. E. Horwood Verlag, New York 1994, ISBN 0-13-106360-X.
- Richard O. Duda, Peter E. Hart, David G. Stork: Pattern Classification. Wiley, New York 2001, ISBN 0-471-05669-3.
- David Barber: Bayesian Reasoning and Machine Learning. Cambridge University Press, Cambridge 2012, ISBN 978-0-521-51814-7.
- Arthur L. Samuel (1959): Some studies in machine learning using the game of checkers. IBM J Res Dev 3:210–229. doi:10.1147/rd.33.0210.
- Alexander L. Fradkov: Early History of Machine Learning. IFAC-PapersOnLine, Volume 53, Issue 2, 2020, Pages 1385-1390, doi:10.1016/j.ifacol.2020.12.1888.
Weblinks
- Machine Learning Crash Course. In: developers.google.com. Abgerufen am 6. November 2018 (englisch).
- Heinrich Vasce: Machine Learning - Grundlagen. In: Computerwoche. 13. Juli 2017, abgerufen am 16. Januar 2019.
- golem.de, Miroslav Stimac: So steigen Entwickler in Machine Learning ein, 12. November 2018
- Introduction to Machine Learning (englisch)
- Maschinen lernen – ohne Verstand ans Ziel, Wissenschaftsfeature, Deutschlandfunk, 10. April 2016. Audio, Manuskript
Einzelnachweise
- Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani: An Introduction to Statistical Learning. Springer, 2013, S. vii (englisch, bcf.usc.edu (Memento des vom 23. Juni 2019 im Internet Archive) [abgerufen am 17. Februar 2024]).
- Jörg Frochte: Maschinelles Lernen - Grundlagen und Algorithmen in Python. 3. Auflage. Carl Hanser, München 2021, ISBN 978-3-446-46144-4, S. 21–27.
- Pat Langley: The changing science of machine learning. In: Machine Learning. Band 82, Nr. 3, 18. Februar 2011, S. 275–279, doi:10.1007/s10994-011-5242-y.
- Danilo Bzdok, Naomi Altman, Martin Krzywinski: Statistics versus Machine Learning. In: Nature Methods. 15. Jahrgang, Nr. 4, 2018, S. 233–234, doi:10.1038/nmeth.4642, PMID 30100822, PMC 6082636 (freier Volltext) – (englisch).
- What is Machine Learning? In: IBM. Abgerufen am 14. Februar 2024 (amerikanisches Englisch).
- Ralf Otte: Künstliche Intelligenz für Dummies. 1. Auflage. WILEY, Weinheim 2019, ISBN 978-3-527-71494-0, S. 57.
- ftp://ftp.sas.com/pub/neural/FAQ.html#questions
- Tobias Reitmaier: Aktives Lernen für Klassifikationsprobleme unter der Nutzung von Strukturinformationen. kassel university press, Kassel 2015, ISBN 978-3-86219-999-0, S. 1 (Google books).
- Lillian Pierson: Data Science für Dummies. 1. Auflage. Wiley-VCH Verlag, Weinheim 2016, ISBN 978-3-527-80675-1, S. 105 f. (Google books).
- Ralf Mikut: Data Mining in der Medizin und Medizintechnik. KIT Scientific Publishing, 2008, ISBN 978-3-86644-253-5, S. 34 (Google books).
- Aurélien Géron: Praxiseinstieg Machine Learning. 3. Auflage. dpunkt Verlag, Heidelberg 2023, ISBN 978-3-96009-212-4, S. 42–43.
- Paul Fischer: Algorithmisches Lernen. Springer-Verlag, 2013, ISBN 978-3-663-11956-2, S. 6–7 (Google books).
- Richard S. Sutton: Reinforcement learning : an introduction. Second edition Auflage. Cambridge, Massachusetts 2018, ISBN 978-0-262-03924-6.
- Machine Learning: Definition, Algorithmen, Methoden und Beispiele. 11. August 2020, abgerufen am 31. Januar 2022.
- Marco Wiering, Martijn van Otterlo: Reinforcement learning : state-of-the-art. Springer, Berlin 2012, ISBN 978-3-642-27645-3.
- ftp://ftp.sas.com/pub/neural/FAQ2.html#A_styles
- Larry Hardesty: Explained: Neural networks. MIT News Office, 14. April 2017, abgerufen am 20. Februar 2024 (englisch).