Multi Media Extension
Die Multi Media Extension (kurz MMX) ist eine Anfang 1997 von Intel auf den Markt gebrachte SIMD-Erweiterung des IA-32-Befehlssatzes, bei der Befehle stets auf mehrere Daten gleichzeitig angewendet werden. Ursprünglich stand das Kürzel MMX für Matrix Math Extensions, wurde allerdings von Intel marketingbedingt in Multi Media Extension umbenannt.[1]

MMX verwendet keine neuen physischen Prozessorregister, sondern funktioniert die Register des mathematischen Koprozessors (FPU) um. Intel entwarf für MMX 57 neue Befehle zum Verarbeiten von Ganzzahlen und führte vier neue Vektor-Datenformate ein. MMX-Befehle unterstützen Sättigungsarithmetik.
MMX wurde nach seiner Einführung von der Software-Industrie nur zögerlich unterstützt und war schon nach drei Jahren durch Intels eigene Fortentwicklungen SSE und AMDs 3DNow! überholt. Benchmarks zu seiner Performance wiesen eine große Bandbreite auf.
Anforderungen von Multimediaanwendungen
Die Anforderungen des Multimedia- und Kommunikationsbereiches stellen an ein Computersystem und damit den Prozessor teilweise andere und neue Anforderungen. Die Verarbeitung der Daten ist meist hochgradig parallelisierbar.[2] So sind z. B. bei einem Videoschnitt die Operationen für die vielen einzelnen Bildpunkte identisch. Theoretisch optimal wäre hier die Ausführung mittels eines einzigen auf alle Punkte anzuwendenden Befehles. Die erforderlichen Operationen sind häufig keine einfachen, einzelnen Anweisungen, sondern eher umfangreichere Befehlsketten. Das Einblenden eines Bildes vor einem Hintergrund ist beispielsweise ein komplexer Vorgang aus Maskenbildung mittels XOR, Vorbereitung des Hintergrundes mittels AND und NOT sowie der Überlagerung der Teilbilder durch OR. Diesen Anforderungen wird durch die Bereitstellung neuer komplexer Befehle entsprochen. So vereinigt z. B. der MMX-Befehl PANDN eine Invertierung und Und-Verknüpfung der Form x = y AND (NOT x).
Realisierung
Intel schuf mit MMX ein neues Konzept zur Verwendung bereits existierender Register, neue Datenformate, einen erweiterten Befehlssatz und die Wahl zwischen verschiedenen arithmetischen Möglichkeiten (Saturation-Mode und Wrap-around-Mode). Kleinere interne, nicht den Befehlsumfang betreffende Unterschiede bestehen zwischen den (nicht offiziell so benannten) Versionen MMX 1.0 und 2.0 der verschiedenen Pentium-Prozessoren. Noch wesentlich weiter entwickelt findet sich der MMX-Ansatz in den ASICs (wo er ursprünglich herkommt) sowie in den AltiVec-Einheiten von modernen PowerPC-CPUs – oder auf Grafikkarten.
Neue Datenformate
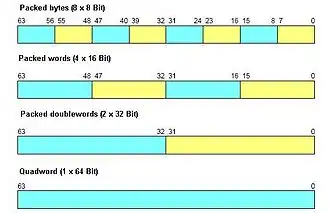
Es wurden für MMX vier neue Datenformate: PackedByte, PackedWord, PackedDoubleWord und QuadWord geschaffen, mit denen es möglich ist, bis zu 64 Bit große Integer-Datenpakete auf einmal zu bearbeiten.[3] Diese Formate sind im Prinzip nur andere Bezeichnungen für bereits existierende Formate. Die neue Nomenklatur zeigt an, dass mit MMX nicht einzelne Daten bzw. Zahlen, sondern Datenfelder bearbeitet werden. Im Prinzip ist ein QuadWord nur ein 64-Bit-Feld, das man auch DoubleLongInt hätte nennen können; ein ShortPackedWord ist eigentlich ein ShortPackedInteger.[4]
Registerverwendung
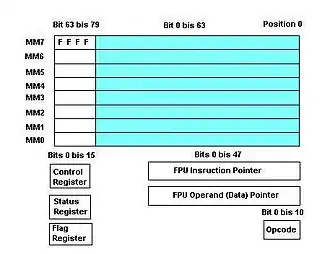
Für die Datenmanipulation wurden zusätzliche 64-Bit-Register MM0 bis MM7 geschaffen,[3] die allerdings mit den 80-Bit-Registern R0 bis R7 der FPU physisch identisch sind. Dabei werden von MMX nur je acht Byte der je zehn Byte breiten FPU-Register (also nur der Mantissenbereich von FPU-Werten) genutzt. Die beiden restlichen Bytes werden unter MMX auf den hexadezimalen Wert FFFF gesetzt. Auch die übrigen FPU-Register, wie die 16 Bit breiten Control-, Status- und Tag-Register, das 11 Bit breite Op-Register sowie die beiden 48 Bit breiten Pointer-Register haben bei MMX-Anwendungen keine bzw. eine in seltenen Fällen eingeschränkte oder anders zu interpretierende Bedeutung der hier anfallenden Werte.[5]
Wechsel zwischen FPU und MMX
Vor einem Wechsel zu einer MMX-Anwendung sollte zuerst geprüft werden, ob SIMD-Erweiterungen und speziell MMX vom System unterstützt werden. Dies ist durch den seit dem Pentium vorhandenen Befehl CPUID unter Übergabe des Wertes 1 im Register EAX möglich.[6][7]
MOV eax, 1 ; Es soll das Feature-Flag abgefragt werden
CPUID ; CPUID-Befehl ausführen
TEST edx, 00800000h ; Ist Bit 23 im Register edx gesetzt?
JNZ MMX_kompatibel ; Wenn ja, dann ist der Prozessor MMX-kompatibel
Möchte man nach einem positiven Test auf MMX-Fähigkeit diese nutzen, sollten als Nächstes die FPU-Daten durch den Befehl FXSAVE in einen 512 Byte großen Speicherbereich gesichert werden. Über die beiden von MMX nicht verwendeten Bytes in jedem Register wird eine MMX-Anwendung abgesichert, d. h. einer FPU-Anwendung angezeigt. Ein expliziter Befehl zum Wechsel in eine MMX-Anwendung existiert allerdings nicht. Eventuell auftretenden FPU-Befehlen während einer MMX-Anwendung wird der Status NaN (Not a Number) übersandt. Störende FPU-Befehle bleiben so meist relativ folgenlos.
Nach Beendigung der Anwendung sollten durch FXSTOR die zuvor durch FXSAVE gesicherten FPU-Daten wiederhergestellt werden. Zur Signalisierung einer Freigabe von MMX an anstehende FPU-Anwendungen existiert auch der allerdings nicht zwingend vorgeschriebene und nicht immer notwendige MMX-Befehl EMMS. Dieser kann auch innerhalb einer MMX-Anwendung – wenn z. B. eine MMX-Anwendung eine API aufruft, welche ihrerseits FPU-Befehle verwendet – nötig sein.[8]
Einsatz in Betriebssystemen
In Multitasking-Betriebssystemen müssen bei einem Kontextwechsel sämtliche Registerinhalte in einem speziellen Speicherbereich gesichert werden. Da eine Änderung dieses Speicherbereiches von sämtlichen Betriebssystemen hätte unterstützt werden müssen, wurde ein „Trick“ eingesetzt, der MMX auch ohne Betriebssystemunterstützung erlaubt: Es wurden nach außen die MMX-Register auf die acht Gleitkomma-Register der FPU abgebildet. Damit sind die eigentlichen FPU-Register nicht mehr verfügbar, sobald ein Programm MMX benutzt.[6] Neuere Befehlssatzerweiterung wie SSE benutzen komplett eigene Register und benötigen somit zwingend eine Unterstützung des Betriebssystems. Auch lässt sich die Überdeckung der Gleitkomma-Register durch die MMX-Register bei neueren Prozessoren abschalten.
Saturation-Mode und Wrap-around-Mode
Der MMX-Befehlsvorrat enthält Befehle, die den Saturation-Mode anwenden, und Befehle, die im Wrap-around Mode arbeiten. So führt z. B. der MMX-Befehl PADDB eine Addition zweier Packed-Bytes im Wrap-around-Mode aus, während PADDSB Selbiges im Saturation-Mode macht.
Der Saturation-Mode bedeutet, dass eine Zahl beim Überschreiten ihres größten oder kleinsten Wertes nicht überläuft, sondern diesen größten bzw. kleinsten möglichen Wert annimmt.
Ein Anwendungsbeispiel: Bei einem Fade-Out-Effekt von Bildern könnte man beispielsweise immer zwei Pixel mit 32 Bit Farbtiefe gleichzeitig um einen gewissen Wert verdunkeln. Durch die Saturation muss man nicht kontrollieren, ob die Pixel bereits schwarz sind (Beispiele: oder ). Dadurch und durch die parallele Verarbeitung mehrerer Werte kann die Geschwindigkeit der Berechnungen erheblich gesteigert werden.


Im Wrap-around-Mode wird bei einem Überlauf bzw. Unterlauf der Übertrag nicht berücksichtigt. So ergibt bei einem Maximalwert von einem Byte (dezimal 256) die Addition das Ergebnis 1. Binär ausgedrückt ergibt , von dem das höchstwertige Bit (hier in Klammern) unberücksichtigt bleibt, was zum Ergebnis 00000001 (also dezimal 1) führt.


Angabe der Operanden
Ein wesentlicher Unterschied zwischen FPU- und MMX-Anwendungen besteht darin, in welcher Form die Befehle ihre Operanden erhalten. Hinter vielen FPU-Befehlen stehen keine expliziten Operanden. Diese holen sich die Befehle über einen Stackpointer (top of the stack) aus den Bits 11 bis 13 des Status-Registers.[9] MMX-Befehle arbeiten dagegen, ebenso wie CPU-Befehle, mit explizit nach dem Befehl angegebenen Operanden.[5]
Ein MMX-Befehl kann keinen, einen oder zwei Quell- und Zieloperanden aufweisen.[10] Dies können MMX-Register (MMX), Allzweckregister (Reg), Speicherstellen (Mem), oder Konstanten (Const) unterschiedlicher Größe (8, 16, 32 oder 64 Bit) sein. Welche Operanden für einen speziellen Befehl zulässig sind, ist unterschiedlich und in Referenzbüchern vermerkt. Eine Angabe wie
Befehl Mem32, MMX Befehl MMX, Reg32 Befehl Reg32, MMX
würde z. B. besagen, dass die Operation (Befehl) von einem MMX-Register zu einem 32-Bit-Allzweckregister, von einem 32-Bit-Allzweckregister zu einem MMX-Register und umgekehrt möglich ist.
Zeitverhalten
Die meisten MMX-Befehle werden in nur einem Prozessorzyklus verarbeitet. Die Multiplikationsbefehle brauchen drei Zyklen, bis das Ergebnis zur Verfügung steht; es kann aber nach jedem Zyklus eine neue Multiplikation in die Pipeline nachgeschoben werden (Pentium MMX bis Pentium III).
Befehlssatz
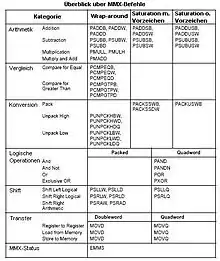
Insgesamt 24 neue Befehle können mit den verschiedenen Datentypen umgehen, was zu den von Intel angegebenen 57 Befehlen führt. Von diesen 24 Befehlen unterscheiden sich etliche nur durch unterschiedliche Berücksichtigung der Vorzeichen und der Überlaufart, so dass im Prinzip nur 15 Grundoperationen übrigbleiben.
Da MMX mit gepackten Daten arbeitet, beginnen die meisten Befehle – zwecks Unterscheidung von den mit F beginnenden FPU-Instruktionen – mit einem P. MMX-Befehle bestehen außer dem führenden P optional aus den Buchstaben B, W, D oder Q für das Datenformat, einem CPU-ähnlichen Befehlswort (wie z. B. ADD oder CMP) und aus S für vorzeichenbehafteten bzw. US für vorzeichenlosen Saturation-Mode. So besagt z. B. der Befehl PADDSW: P für Packed, ADD für Addition, S für vorzeichenbehafteten Saturation-Mode angewandt auf das Datum eines Words. Der MMX-Befehlssatz umfasst Anweisungen[11] zum:
- arithmetischen Manipulieren von Daten
- logischen Manipulieren von Daten
- Datenaustausch
- Datenvergleich
- Datenkonversion
- MMX-Status
Detailfragen zum Befehlsvorrat sind dem Intel Architecture Software Developer’s Manual, Volume 2 – Instruction Set zu entnehmen, siehe im Abschnitt Literatur.
Arithmetische Befehle
Zur Addition im Wrap-around-Mode existieren drei Befehle (PADDB, PADDW, PADDD) für die Datentypen PackedByte, PackedWord, und PackedDoubleWord. Im Saturation-Mode existieren Befehle für die vorzeichenbehaftete (PADDSB, PADDSW) sowie vorzeichenlose (PADDUSB, PADDUSW) Addition von PackedBytes und PackedWords. Ein Befehl für die Addition von DoubleWords ist nicht vorhanden. In beiden Modi wird kein Hinweis auf einen Über- oder Unterlauf des Wertebereichs, z. B. durch Setzen von Flags, gegeben.[12]
Die Befehle zur Subtraktion sind analog zur Addition gestaltet.
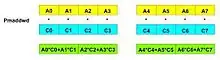
PMADDWD im DetailBei der Multiplikation besteht das Problem, dass die Ergebnisse die Größe der Register von 64-Bit übersteigen können. Dies wurde dadurch gelöst, dass der höherwertige und der niederwertige Anteil des Ergebnisses in zwei verschiedenen Registern gespeichert wird. Für die Multiplikation und die Verwendung des niederwertigen Anteils wird PMULLW (Multiply Packed Word and Store Low) und für den höherwertigen Anteil PMULHW (Multiply Packed Word and Store High) verwandt.[13]
Der Befehl PMADDWD multipliziert vier Paare von 16-Bit-Worten und addiert paarweise die Ergebnisse auf.
Die Befehle zur Verschiebung funktionieren, mit Ausnahme des in MMX dabei nicht gesetzten Carry-Flags, analog zu den Schiebe-Befehlen der CPU wie z. B. SLL, SRL und SRA. Sie sind nur auf Words, DoubleWords und QuadWords, nicht aber auf Bytes, anwendbar. Für das logische Verschieben nach links werden PSLLW und PSLLD und für die umgekehrte Richtung PSRLW und PSRLD angewandt. Für das arithmetische Verschieben stehen PSRAW und PSRAD zur Verfügung, für die logische Verschiebung von QuadWords PSLLQ und PSRLQ.[10]
Logische Operationen
Die Bit-Manipulationsbefehle sind identisch mit den CPU-Befehlen AND, OR und XOR, nur werden von ihnen gleich 64 Bit, also ein QuadWord, auf einmal bearbeitet. Eine MMX-Entsprechung zum CPU-Befehl NOT existiert nicht. Der einzige MMX-Befehl ohne Entsprechung im CPU-Befehlsvorrat ist PANDN, der eine Negation des ersten Operanden mit anschließender AND-Verknüpfung mit dem zweiten Operanden in folgender Form darstellt: x = y AND (NOT x)[14]
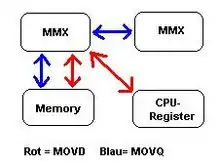
Datenaustausch
Dazu existieren analog zum CPU-Befehl MOV die beiden Befehle MOVD und MOVQ für DoubleWords und QuadWords. Bedingt durch die Rechnerarchitektur – also die unterschiedliche Größe von 64-Bit-MMX-Registern, 32-Bit-Allzweckregistern und dem 32-Bit-Adressbus – sind beide Befehle gewissen Beschränkungen in Bezug auf die zulässigen Operanden unterworfen.[15]
MOVD kann nicht zum Datenaustausch zwischen zwei MMX-Registern verwandt werden, da es für MMX-Register nur 64-Bit-Daten gibt. Er ermöglicht also nur den Austausch zwischen einem MMX-Register und 32-Bit-Allzweckregistern und Speicherstellen in beiden Richtungen.[16] Die möglichen Formen sind also:
MOVD MMX, Mem32 MOVD Mem32, MMX MOVD MMX, Reg32 MOVD Reg32, MMX
Dabei sind immer nur die niederwertigen Bits 0 bis 31 des MMX-Registers betroffen. Beim Verschieben von Daten aus einem MMX-Register werden also nur diese Bits verwandt. Beim Verschieben von Daten in das MMX-Register wird der höherwertige Anteil (Bits 32 bis 64) gelöscht, also auf Null gesetzt.
MOVQ erlaubt einen bidirektionalen Datenaustausch aller 64 Bit zwischen MMX-Registern und Speicherstellen. Ein Datenaustausch mit den 32-Bit-Allzweckregistern ist nicht vorgesehen. Die möglichen Formen sind damit:
MOVQ MMX, MMX MOVQ MMX, Mem64 MOVQ Mem64, MMX
Datenvergleich
Die MMX-Befehle zum Datenvergleich sind weniger flexibel und mächtig als die entsprechenden CPU- und FPU-Befehle. Es ist nur vorgesehen, beide Operanden auf Gleichheit zu testen oder prüfen zu lassen, ob der Wert im ersten Operand größer als im zweiten ist. Beide Vergleichsmöglichkeiten sind für die drei Formate Byte, Word und DoubleWord verfügbar. Somit ergeben sich folgende Befehle: PCMPEQB, PCMPEQW, PCMPEQD, PCMPGTB, PCMPGTW und PCMPGTD (EQ steht hierbei jeweils für equal, GT für greater). Als erster Operand ist nur ein MMX-Register, als zweiter ein MMX-Register oder eine 64-Bit-Speicherstelle erlaubt.
Ein wesentlicher Unterschied zu CPU und FPU besteht in der Art, wie das Ergebnis des Vergleichs übergeben wird. Es wird nicht durch das Setzen von Flags oder das Setzen einzelner Bits (z. B. im Statusregister der FPU) angezeigt, sondern im ersten Operanden – also einem MMX-Register – abgelegt. Führt der Vergleich zu einem wahren Ergebnis, wird dort der hexadezimale Wert FF bzw. FFFF oder FFFFFFFF eingetragen. Im anderen Fall werden Nullen eingefügt. Ein Vergleich von zwei DoubleWords auf Gleichheit durch PCMPEQD MMx, MMy ließe sich in seinem Ablauf demnach folgendermaßen ausdrücken:
IF MMx [31..00] > MMy [31..00] THEN MMx [31..00] := $FFFFFFFF
ELSE MMx [31..00] := $00000000;
IF MMx [63..32] > MMy [63..32] THEN MMx [63..32] := $FFFFFFFF
ELSE MMx [63..32] := $00000000;
Datenkonversion
MMX-Befehle ermöglichen die Konvertierung eines Datums in ein kleineres oder größeres, wobei eine Konvertierung in ein kleineres Datenformat natürlich immer einen Datenverlust zur Folge hat.
- Für die Konvertierung in ein kleineres Datum stehen die Befehle
PACKSSWB,PACKSSDWundPACKUSWBfür die Umwandlung von Word zu Byte und DoubleWord zu Word zur Verfügung. Zwecks Erhaltung des Vorzeichens wird dabei das höchstwertige Bit des Zieldatums nicht verwendet. Damit ist nur die Hälfte des Wertebereichs verfügbar. Die Befehle saturieren deshalb Werte, welche diesen Bereich über- oder unterschreiten. So setzt z. B.PUNBKHBWalle Werte, die −128 unterschreiten auf −128 und alle Werte, die 127 überschreiten, auf 127.PACKUSWB(Pack with Unsigned Saturation Word to Byte) berücksichtigt das Vorzeichen nicht, saturiert aber dennoch.
- Die Konvertierung in ein größeres Format ist von Byte zu Word, Word zu DoubleWord und DoubleWord zu QuadWord möglich. Dabei existiert jeweils ein Befehl für die Umwandlung des niederwertigen und des höherwertigen Teil der Daten: Ersteres decken die drei Befehle
PUNPCKHBW,PUNPCKHWDundPUNPCKHDQab, LetzteresPUNPCKLBW,PUNPCKLWDundPUNPCKLDQ.[10]
MMX-Status
Die drei Befehle zum MMX-Status EMMS, FXSAVE und FXRSTOR besitzen keine Operanden. EMMS ist eine Art Aufräumbefehl nach Beendigung einer MMX-Anwendung. FXSAVE und FXRSTOR dienen jeweils zum Sichern und Wiederherstellen FPU-spezifischer Daten, Flags und Register, siehe hierzu auch im Abschnitt Wechsel zwischen FPU und MMX.
Die beiden Befehle FXSAVE und FXRSTOR wurden erst mit dem Deschutes Kern des Pentium II eingeführt. In früheren CPUs stehen sie nicht zur Verfügung.
Exceptions
Da MMX-Befehle sich nicht grundlegend von CPU-Befehlen unterscheiden, können sie auch grundsätzlich dieselben Exceptions auslösen. FPU-spezifische, Gleitkommazahlen betreffende Exceptions wie z. B. Ausnahmesituationen bei Denormalisierungen können bei Benutzung der Register durch MMX nicht auftreten.[17]
CPUs mit MMX
Da MMX die erste Erweiterung der x86-Architektur ist, besitzen eigentlich alle CPUs der letzten Jahre MMX. Eine vollständige Liste aller CPUs mit MMX würde also den Rahmen sprengen. An dieser Stelle sei allerdings auf die Liste von Mikroprozessoren verwiesen.
Nachfolgend eine Übersicht, ab welcher CPU-Familie die jeweiligen Hersteller MMX integriert haben:
Programmiersprachen
Zur Umsetzung der erweiterten und erhöhten Potenziale eines neuen Prozessorkonzeptes wie MMX in optimierte Anwendungssoftware ist es erforderlich, dass die erweiterten Möglichkeiten der Maschinensprache auch von den neuen Versionen der diversen höheren Programmiersprachen unterschiedlichsten Abstraktionsniveaus und ihren Compilern unterstützt werden.
Die Sprachen können sich dabei einerseits darauf beschränken, die Möglichkeiten von MMX im Kompilierungsprozess umzusetzen, den Befehlsvorrat der jeweiligen Sprache aber nicht zu erweitern. Für den Programmierer ändert sich dadurch recht wenig, er muss lediglich aus Gründen der Abwärtskompatibilität vor der Kompilierung angeben, ob MMX im Zielcode verwendet werden soll oder nicht.[20]
Eine Sprache kann aber auch ihren Befehlsvorrat erweitern und neue, speziell die Stärken von MMX unterstützende Konzepte und Befehle für das Schreiben des Quellcodes implementieren. So stellt z. B. Free Pascal[21] vordefinierte Array-Typen speziell für MMX und 3DNow! bereit.[22] Vector Pascal ermöglicht parallele Operationen auf Daten.
Im systemnahen Sprachbereich unterstützte der Microsoft Macro Assembler schon ein dreiviertel Jahr nach Markteinführung von MMX in Version 6.12 die neuen Möglichkeiten von MMX. Auch der Flat Assembler und NASM unterstützten später MMX. Intel unterstützte in seinen eigenen C-Compilern und später in C++[23] relativ zügig MMX. Auch der VectorC Compiler[24] von Codeplay unterstützt die Vektorisierung und optimiert C-Quellcode bei der Übersetzung für MMX. Andere Programmiersprachen folgten später mit der Umsetzung der Möglichkeiten von MMX. Die MMX-Unterstützung in Microsofts C++-Compiler wurde allerdings nicht mehr für 64-Bit-Anwendungen übernommen.[25]
Einsatz in Software
MMX wurde, ebenso wie AMDs 3DNow!, nicht im von Intel erhofften Umfang von der Softwareindustrie eingesetzt. Nur bei wenigen Produkten ist ein Vermerk wie „Optimiert für MMX“ explizit zu finden. Am ehesten wurde es noch bei Spielen und Video-Anwendungen wie z. B. Ulead VideoStudio eingesetzt.[26] Eine der Anwendungen, die die MMX-Möglichkeiten relativ schnell implementierten, war Adobe Photoshop (siehe dazu auch den Abschnitt Leistung).
Leistung
Angaben zur Leistung sind stark vom jeweiligen Gesamtsystem, den getesteten Anwendungsbereichen und Anwendungen, den angewandten Algorithmen, der Testmethode bzw. der testenden Firma, und vielen anderen Randbedingungen abhängig.[27] Intel selbst verspricht bei MMX-Prozessoren 10–20 % mehr Leistung bei herkömmlicher Software und bis zu 60 % mehr bei MMX-optimierter Software.[28][29] Gerade aber bei 3D-Grafik mit vielen Gleitkommaberechnungen bringt MMX (siehe auch Grafik) kaum eine Leistungssteigerung, da das Umschalten zwischen MMX- und FPU-Arithmetik („Context Switch“) mit bis zu 50 Taktzyklen[7] relativ viel Zeit in Anspruch nehmen kann.[30]
Sreraman und Govindarajan haben im Jahr 2000 in Bezug auf die Vektorisierung unter der Sprache C Leistungssteigerungen vom Faktor 2 bis 6,5 für MMX ermittelt.[31] Bei Benutzung von Intel-eigenen Programmbibliotheken für Signal- und Bildbearbeitung bringt MMX Verbesserungen der Performance vom Faktor 1,5 bis 2, bei Grafikanwendungen zwischen 4 und 6.[32] Nach anderen Untersuchungen bringt die Verwendung von MMX Performancevorteile von Faktoren zwischen 1,2 und 1,75.[33] Beim MPEG-Decoding beschränkt sich laut Intel der Performencegewinn durch MMX auf 40 Prozent. Somit kann MMX nur bei bestimmten Aufgabenstellungen deutliche Leistungsvorteile gegenüber nichtoptimierter Software bringen.
Testergebnisse können sogar im Vergleich verschiedener Versionen derselben Software stark schwanken. So ergaben sich bei einem Test des für MMX optimierten Adobe Photoshop Version 4.0 bei den meisten Filtern Performancegewinne zwischen 5 und 20 Prozent.[34] In Version 4.0.1 liefen manche Aktionen unter MMX dagegen überraschenderweise langsamer als ohne MMX-Unterstützung.[35]
Nach MMX
MMX konnte schon bald den gestiegenen Anforderungen schnell wechselnder Grafik in hochauflösender Form, wie sie z. B. Spiele stellen, nicht mehr genügen. Deshalb führte Intel mit der Einführung des Pentium-III-Prozessors Anfang 1999 die SSE-Technologie ein. Dabei wurden acht – auch physisch – neue, CPU- und FPU-unabhängige 128 Bit breite Register geschaffen. Es wurde sowohl der MMX-Befehlssatz erweitert als auch gänzlich neue Befehle geschaffen. SSE erweiterte außerdem das ausschließliche Arbeiten von MMX mit Ganzzahlen (Integer) auf Gleitkommazahlen. Spätere Nachfolgeversionen erweiterten zudem stetig die Fähigkeiten von SSE.
Das von AMD 1998 mit dem AMD K6-2 eingeführte 3DNow! nutzte ebenso wie MMX die Register der FPU, allerdings in einer der FPU-adäquaten Art zur Bearbeitung von Gleitkommazahlen. Die nachfolgenden Versionen von 3DNow! beseitigten Inkompatibilitäten zu Intels SSE-Konzept.
Erweiterung des MMX-Befehlsvorrats unter SSE
Mit SSE wurden zwölf neue Befehle für den MMX-Modus eingeführt, welche nicht mit den neuen XMM-Registern von SSE, sondern ausschließlich mit den alten MMX- bzw. FPU-Registern arbeiten.
PAVGBundPAVGWbilden den gerundeten Mittelwert zweier Operanden.PEXTRWundPINSRWdienen der Extraktion und Insertion von Words.PMAXSW,PMAXUB,PMINSW, undPMINUBberechnen Minima und Maxima zweier vorzeichenbehafteter Words bzw. vorzeichenloser Bytes.PMOVMSKBerzeugt aus den Most Significant Bits eines Short Packed Bytes eine Maske.PMULHUWarbeitet wie der alte BefehlPMULHW, verwendet im Gegensatz dazu aber zwei vorzeichenlose Words.PSADWBberechnet für zwei Werte die absoluten Werte der Differenzen ihrer einzelnen Bytes und addiert danach die Summe dieser Differenzen auf.PSHUFWmischt die Einzelbestandteile zweier 64-Bit-Werte nach Regeln, die über einen dritten Befehlsoperanden übergeben werden.[36][37]
SSE2 bis SSE4
Mit SSE2 wurde ein vereinheitlichter Befehlssatz verwirklicht, der ebenso auf die 128 Bit breiten XMM- wie auf 64 Bit breiten MMX-Register verwandt werden kann. Manche Befehle erlauben sogar die gleichzeitige Verwendung beider Registergruppen, z. B. der Konvertierungsbefehl CVPD2PI MMX, XMM.[38] Mit SSE4 wurde die Unterstützung von MMX dann aber beendet.
Literatur
- David Bistry, Carole Delong, Mickey Gutman: Complete Guide to MMX Technology. McGraw-Hill, 1997, ISBN 0-07-006192-0
- Richard Blum: Professional Assembly Language. Wiley Publishing, 2005, ISBN 0-7645-7901-0
- Paul Cockshott, Kenneth Renfrew: SIMD Programming Manual for Linux and Windows. Springer, Berlin 2004, ISBN 1-85233-794-X
- Rohan Coelho, Maher Hawash: DirectX, RDX, RSX, and MMX Technology – A Jumpstart Guide to High Performance APIs. Addison-Wesley, Amsterdam 1997, ISBN 0-201-30944-0
- Randall Hyde: The Art of Assembly Language. No Starch Press, 2003, ISBN 1-886411-97-2
- Intel: Intel Architecture Software Developer’s Manual, Volume 1 – Basic Architecture, Bestellnummer 243190, 1999
- Intel: Intel Architecture Software Developer’s Manual, Volume 2 – Instruction Set, Bestellnummer 243191, 1999
- Intel: Intel Architecture Software Developer’s Manual, Volume 3 – System Programming Guide, Bestellnummer 243192, 1999
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, ISBN 3-8273-2026-7
- Shreekant S. Thakkar: Programmer’s Guide for Internet Streaming SIMD Extensions. Wiley & Sons, 2000, ISBN 0-471-37524-1
- Bliss Sloan: Developing for MMX Technology. Que, 1997, ISBN 0-7897-1302-0
- Ralf Weber: Pentium, MMX, AMD konfigurieren. Sybex, 1997, ISBN 3-8155-7106-5
- Joachim Rohde: Assembler GE-PACKT. mitp-Verlag, 2001, ISBN 3-8266-0786-4.
Joachim Rohde: Assembler GE-PACKT. 2. Auflage. mitp-Verlag, 2007, ISBN 978-3-8266-1756-0
Weblinks
- Rasmus Hahn, Bernd Peterson, Andreas Micklei: Prozessorerweiterungen für Multimedia – Workstationarchitekturen für Multimediasysteme WS 96/97
- Andreas Roskosch: Prozessoren. Ausarbeitung eines Proseminars an der Technischen Universität Chemnitz, von 1997
- Übersicht zu Intel-Pentium-MMX-Prozessoren
- Bernd Leitenberger: SIMD und VLIW. Überblick über einige SIMD-Technologien
- Jens Hohmuth: MMX-Tutorial. Anleitung zur Nutzung vom MMX bei der Westsächsischen Hochschule Zwickau, vom 2. Januar 1999
- Pei Qi, Yang Wang: Accelerating 3D Geometry Transformation with Intel MMX Technology. (PDF; 195 kB)
Einzelnachweise
- Controversy brews over use of MMX moniker (Memento vom 19. Juli 2012 im Webarchiv archive.today). Bnet, 6. Januar 1997
- Richard Blum: Professional Assembly Language. Wiley Publishing, 2005, S. 482
- Intel Architecture Software Developer’s Manual, Volume 1 - Basic Architecture, Bestellnummer 243190, 1999, Kapitel 8: Programming with the Intel MMX Technology, S. 216 f.
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, S. 274 f.
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, S. 276–278
- Randall Hyde: The Art of Assembly Language, No Starch Press, 2003, Seite 710–712
- Jens Hohmuth: MMX-Tutorial (Memento des vom 8. Februar 2009 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis., Anleitung zur Nutzung vom MMX bei der Westsächsischen Hochschule Zwickau, vom 2. Januar 1999
- Randall Hyde: The Art of Assembly Language. No Starch Press, 2003, S. 734
- Don Brumm, Leo J. Scanlon: 80486 Programming. Windcrest, 1991, S. 24
- Intel Architecture Software Developer’s Manual, Volume 1 – Basic Architecture, Bestellnummer 243190, 1999, Kapitel 8: Programming with the Intel MMX Technology, Seite 221 ff.
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, S. 281
- Klaus Wüst: Mikroprozessortechnik – Grundlagen, Architekturen und Programmierung von Mikroprozessoren, Mikrocontrollern und Signalprozessoren. vieweg, 2006, S. 214–218
- Richard Blum: Professional Assembly Language. Wiley Publishing, 2005, S. 488 ff.
- Richard Blum: Professional Assembly Language. Wiley Publishing, 2005, S. 494
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, S. 296 ff.
- Randall Hyde: The Art of Assembly Language. No Starch Press, 2003, S. 718 ff.
- David Bistry, Carole Delong, Mickey Gutman: Complete Guide to MMX Technology. McGraw-Hill, 1997, S. 138
- Paul Herrmann: Rechnerarchitektur, vieweg, 2002, Seite 417
- Intel-Pentium-MMX-Prozessoren auf cpu-collection.de
- Shreekant S. Thakkar: Programmer’s Guide for Internet Streaming SIMD Extensions. Wiley & Sons, 2000, S. 72
- Free Pascal Programmer’s Guide, Abschnitt 5.1: Intel MMX support – What is it about? FreePascal.org
- Larry Carter, Jeanne Ferrante: Languages and Compilers for Parallel Computing. S. 400
- Introduction to MMX Programming The Code Project, Beispiele zur Nutzung von MMX mit C++
- Codeplay VectorC Compiler Technology. (Memento des vom 9. Mai 2009 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. Codeplay
- MMX Technology Microsoft Developer Network
- Klaus Dembowski: PC-Werkstatt – Boards, Speicher, Prozessoren. Markt+Technik, 2005, S. 711
- David J. Lilja: Measuring Computer Performance – A pracitioner’s guide. Cambridge University Press, 2000, S. 2 ff.
- Andreas Roskosch: Prozessoren, Abschnitt „MMX im Leistungsvergleich“ (Memento des vom 12. Juli 2010 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- Intel Introduces 11TH Microprocessor with MMX Technology. (Memento des vom 8. September 2008 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. Berkeley Wireless Research Center
- David Bistry, Carole Delong, Mickey Gutman: Complete Guide to MMX Technology. McGraw-Hill, 1997, S. 291
- Paul Cockshott, Kenneth Renfrew: SIMD Programming Manual for Linux and Windows. Springer, Berlin 2004, S. 23
- Alan Conrad Bovik: Handbook of Image & Video Processing. 2005, S. 636
- R. Bhargava, R. Radhakrishnan, B. L. Evans, L. John: Characterization of MMX-enhanced DSP and Multimedia Applications on a General Purpose Processor. Digest of the Workshop on Performance Analysis and Its Impact on Design held in conjunction with ISCA98. (Seite nicht mehr abrufbar, festgestellt im April 2019. Suche in Webarchiven) Info: Der Link wurde automatisch als defekt markiert. Bitte prüfe den Link gemäß Anleitung und entferne dann diesen Hinweis. (PDF) University of Texas at Austin
- Jennis Meyer-Spradow, Andreas Stiller: Großspurig – Ein kritischer Blick auf MMX. (Memento vom 8. Juli 2001 im Internet Archive) In: c’tAusgabe, 1/97, S. 228
- Weniger MMX bei Photoshop. heise online, 9. Juni 1997
- Trutz Eyke Podschun: Die Assembler-Referenz – Kodierung, Dekodierung und Referenz. Addison-Wesley, 2002, S. 231–249
- Intel Architecture Software Developer’s Manual, Volume 2 – Instruction Set. Kapitel 9.3.6: Additional SIMD Integer Instructions, Seite. 246
- Trutz Eyke Podschun: Das Assemblerbuch – Grundlagen, Einführung und Hochsprachenoptimierung. Addison-Wesley, 2002, S. 345 ff.