Graphdatenbank
Eine Graphdatenbank ist eine Datenbank, die Graphen benutzt, um stark vernetzte Informationen darzustellen und abzuspeichern. Ein solcher Graph besteht aus Knoten und Kanten, den Verbindungen zwischen den Knoten. Die zwei bekanntesten Konzepte für Graphdatenbanken sind das Resource Description Framework (RDF) und Labeled-Property Graph (LPG).
Eigenschaften
Graphdatenbanken gehören zu den NoSQL-Datenbanken und priorisieren im Gegensatz zu relationalen Datenbanksystemen die Beziehung zwischen den Daten und vereinfachen dadurch die Abbildung hierarchischer sowie vernetzter Strukturen. Mit Hilfe spezieller Abfragesprachen wie SPARQL, Cypher und GraphQL ermöglichen Graphdatenbanken beispielsweise die Abfrage komplexer Muster, das Traversieren von Graphen sowie die Ermittlung des kürzesten Pfades zwischen zwei Knoten. Durch spezialisierte Graphdatenbanken können bekannte Graphstrukturen wie beispielsweise Cliquen oder Hotspots in einem Graphen deutlich leichter identifiziert werden.
Während andere Datenbanken zur Abfragezeit Beziehungen durch aufwändige Join-Operationen berechnen, speichert eine Graphdatenbank Verbindungen neben den Daten im Modell. Der Zugriff auf Knoten und Kanten in einer nativen Graphdatenbank ist eine effiziente Operation mit konstanter Laufzeit und ermöglicht es, schnell Millionen von Kanten pro Sekunde zu durchlaufen. Unabhängig von der Gesamtgröße der Datenmenge eignen sich Graphdatenbanken hervorragend für die Verwaltung stark verbundener Daten und komplexer Abfragen. Mit nur einem Muster und einer Menge von Startknoten untersuchen Graphdatenbanken die benachbarten Daten um diese anfänglichen Startknoten herum, sammeln und verknüpfen Informationen von Millionen Knoten und Kanten und lassen alle Daten außerhalb des Suchbereichs unberührt.
Graph-Modelle
Graphdatenbanken stellen die Daten dar, wie sie konzeptionell angesehen werden. Dies wird erreicht, indem die Daten in Knoten und seine Beziehungen in Kanten übertragen werden. Eine Graphdatenbank ist eine Datenbank, die auf Graphentheorie basiert. Sie besteht aus einer Menge von Objekten, die Knoten oder Kanten sein können.
Knoten repräsentieren Dinge wie Personen, Unternehmen, Konten oder Fahrzeuge. Sie sind ungefähr das Äquivalent eines Datensatzes, Relation oder Zeile in einer relationalen Datenbank oder eines Dokuments in einer dokumentenorientierten Datenbank.
Kanten sind die Linien, die Knoten mit anderen Knoten verbinden und die Beziehung zwischen ihnen darstellen. Sinnvolle Muster entstehen beim Prüfen der Verbindungen von Knoten, Eigenschaften und Kanten. Die Kanten können entweder gerichtet oder ungerichtet sein. In einem ungerichteten Graphen hat eine Kante, die zwei Knoten verbindet, eine einzige Bedeutung. In einem gerichteten Graphen haben die Kanten, die zwei verschiedene Knoten verbinden, je nach Richtung unterschiedliche Bedeutungen.
Kanten sind das Schlüsselkonzept in Graphdatenbanken, die eine Abstraktion darstellen, die nicht direkt in einem relationalen Modell oder einem Dokumentenmodell implementiert ist. Eigenschaften sind Informationen, die mit Knoten verknüpft sind.
Beispiele
Ein einfaches Beispiel für einen Graphen sind Beziehungen zwischen Menschen (siehe dazu auch Soziogramm). Die Knoten repräsentieren Menschen; jedem Knoten wird dabei der Name der Person zugeordnet. Die Kanten repräsentieren Beziehungen. Sie sind durch einen Typ (kennt, liebt, hasst) ausgezeichnet.
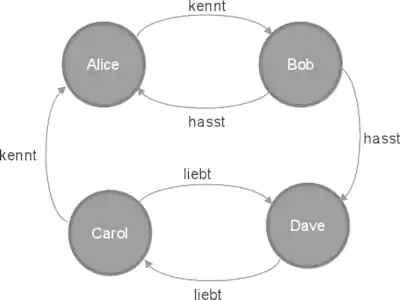
Obiger Graph ist ein gerichteter, benannter Multigraph. Die Kanten mit der Bezeichnung kennt sind im Allgemeinen symmetrisch, wogegen dies für die Beziehungen liebt und hasst jedoch nicht zwangsläufig stimmen muss.
Ein anderes Beispiel sind Netzwerkverbindungen. Jeder Knoten entspricht einem Computer, Switch oder Router. Jede Kante einer Verbindung. Jede Verbindung hat eine Bandbreite. In diesem Fall spricht man auch von gewichteten Graphen.
Labeled-Property-Graph
In einem Labeled-Property-Graph oder einfach Property-Graph können sowohl Knoten als auch Kanten Eigenschaften, sogenannte Properties (bspw. Gewicht: 10 kg, Farbe: Rot, Name: Alice), besitzen. Durch diese Spezialisierung auf Property-Graphen unterscheiden sie sich von den klassischen Datenmodellen der Relationalen Datenbanken.
Resource Description Framework
Im Resource Description Framework (RDF) werden Graphen mit Hilfe von Triplen repräsentiert. Ein Triple besteht aus drei Elementen in der Form Knoten-Kante-Knoten (Subjekt --Prädikat-> Objekt), die als Ressourcen in Form einer weltweit eindeutigen URI oder als anonyme Ressource definiert werden. Um innerhalb einer Datenbank verschiedene Graphen zu verwalten, werden die Triple als Quads gespeichert. Ein Quad erweitert dabei jedes Triple um eine Referenz auf den zugehörigen Graphen. Das oben genannte Beispiel lässt sich etwa wie folgt darstellen:
Alice --kennt-> Bob Bob --hasst-> Alice Bob --hasst-> Dave Carol --kennt-> Alice Carol --liebt-> Dave Dave --liebt-> Carol
Mit Hilfe dieser einfachen Bausteine aus (Subjekt --Prädikat-> Objekt) können sehr komplexe Graphen entwickelt werden, die bei entsprechender Modellierung auch automatische Schlussfolgerungen ermöglichen. Aufbauend auf RDF wurde mit RDF-Schema ein Vokabular entwickelt, um schwache Ontologien zu formalisieren und darüber hinaus lassen sich mit der Web Ontology Language auch vollständig entscheidbare Ontologien beschreiben. Um die Datenqualität und die Einhaltung eines Schemas in komplexen Graphstrukturen zu gewährleisten empfiehlt die W3C den Einsatz von SHACL.
RDF findet eine weite Verbreitung in vielen Webtechniken, wie RSS und im semantischen Web.
SPARQL ist eine standardisierte Abfragesprache im Semantic Web, mit deren Hilfe RDF-Graphen erzeugt, modifiziert und abgefragt werden können.
Abgrenzung
Relationale Datenbanken
Relationale Datenbanken verwalten Relationen (Tabellen) und Tupel (Zeilen). Jede Zeile in einer Tabelle ist ein Datensatz. Jede Zeile besteht aus einer Reihe von Attributswerten (Eigenschaften), den Spalten der Tabelle. Das Relationenschema legt dabei die Anzahl und den Typ der Attribute für eine Relation fest. Beziehungen zwischen Tabellen werden durch Schlüssel realisiert.
Mit SQL existiert eine einheitliche Abfragesprache für relationale Datenbankmanagementsysteme. SQL erlaubt die Selektion von Zeilen mit bestimmten Eigenschaften.
Es ist möglich, Graphen in relationalen Datenbanken abzubilden. Für obiges Beispiel eines sozialen Netzwerks wählt man für die Personen eine Tabelle PERSON und für die Kanten eine Tabelle BEZIEHUNG. Mit SQL lassen sich alle Knoten (Personen) oder Kanten (Beziehungen) mit vorgegebenen Eigenschaften finden. Um alle indirekten Bekannten zu finden oder einen Pfad zwischen zwei Personen zu bestimmen, können Recursive Common Table Expressions eingesetzt werden (ANSI-SQL 99, DB2, Oracle 11gR2, PostgreSQL, SQL-Server 2008). Damit lassen sich uni- und bidirektionale Graphen durchsuchen. Enthält die Tabelle mit den Kanten auch eine Gewichtung, lässt sich so auch der optimale (kürzeste) Pfad zwischen zwei Knoten mit einer SQL-Abfrage ermitteln.
Demgegenüber verwenden Graphdatenbanken performantere Traversionsalgorithmen zur Selektion bestimmter Knoten. Ausgehend von einem oder mehreren Knoten werden alle oder ausgewählte ausgehende Kanten traversiert.
Objektorientierte Modelle
Mit dem Aufkommen objektorientierter Programmiersprachen wurden zunehmend Objektdatenbanken angeboten. Damit können Objekte aus objektorientierten Sprachen direkt in der Datenbank gehalten werden. Dieses Vorgehen hat Vorteile gegenüber dem relationalen Entwurf, wenn man komplexe Datenobjekte speichern möchte, die nur schwer auf die flachen relationalen Tabellenstrukturen abgebildet werden können. Graphen lassen sich in Objektdatenbanken abbilden, indem man die ausgehenden Kanten als Liste der Zielknoten hält. Es ist jedoch bei diesem Vorgehen nicht möglich, den Kanten selbst Eigenschaften zuzuweisen.
Abfragesprachen
Bisher gibt es keinen Standard für die Abfrage von Graphdatenbanken. Das hat zu einer Vielzahl unterschiedlicher Abfragesprachen und Abfragemöglichkeiten geführt. Wichtige Vertreter sind
- Blueprints – eine Java-API für Eigenschaftsgraphen, die zusammen mit verschiedenen Graphdatenbanken verwendet werden kann.
- Cypher – eine Abfragesprache entwickelt von Neo4j.
- GraphQL – eine SQL-artige Abfragesprache.
- Gremlin – eine Open-Source-Graphen-Programmiersprache, die mit verschiedenen Graphdatenbanken (Neo4j, OrientDB, DEX, JanusGraph) genutzt werden kann.
- GReQL – eine textuelle Graphanfragesprache für Eigenschaftsgraphen, bietet Berechnung regulärer Pfade durch Pfadausdrücke.
- Pipes – ein Datenfluss-Framework für Java auf Basis von Prozessgraphen speziell für die Anfrageverarbeitung auf Property-Graphen.
- Rexster – eine HTTP/REST-Schnittstelle für den Zugriff auf Graphdatenbanken via Internet, die von mehreren Herstellern unterstützt wird.
- SPARQL – vom W3C spezifizierte Abfragesprache für RDF-Datenmodelle.
Siehe auch
Weblinks
- Graph Databases and the Future of Large-Scale Knowledge Management
- What is a Graph Database?
- Social networks in the database: using a graph database
- graph database
- Scaling Online Social Networks without Pains (PDF; 250 kB)
- Large-scale Graph Computing at Google
- On building a stupidly fast graph database
- Renzo Angles, Claudio Gutierrez. Survey of graph database models. ACM Computing Surveys, Feb. 2008.
- Shapes Constraint Language (SHACL)