Base64
Base64 ist ein Verfahren zur Kodierung von 8-Bit-Binärdaten (z. B. ausführbare Programme, ZIP-Dateien oder Bilder) in eine Zeichenfolge, die nur aus lesbaren, Codepage-unabhängigen ASCII-Zeichen besteht.
Es findet im Internet-Standard Multipurpose Internet Mail Extensions (MIME) Anwendung und wird dort zum Versenden von E-Mail-Anhängen verwendet. Nötig ist dies, um den problemlosen Transport von beliebigen Binärdaten zu gewährleisten, da SMTP in seiner ursprünglichen Fassung nur für den Versand von 7-Bit-ASCII-Zeichen ausgelegt war. Durch die Kodierung steigt der Platzbedarf des Datenstroms um 33–36 % (33 % durch die Kodierung selbst, bis zu weitere 3 % durch die im kodierten Datenstrom eingefügten Zeilenumbrüche). Base64 wird zum Beispiel auch zur Kodierung von Benutzernamen und Passwort in der HTTP-Basisauthentifizierung und zur Übertragung von SSH-Server-Zertifikaten verwendet.
Vorgehen bei der Kodierung
Zur Kodierung werden die Zeichen A–Z, a–z, 0–9, + und / verwendet sowie = am Ende. Da diese Zeichen auch im Extended Binary Coded Decimals Interchange Code (EBCDIC) vorkommen (wenn auch an anderen Codepositionen), ist ein verlustfreier Datenaustausch zwischen diesen Plattformen gesichert.
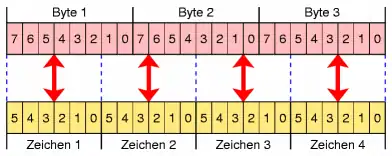
Zur Kodierung werden jeweils drei Byte des Bytestroms (= 24 Bit) in vier 6-Bit-Blöcke aufgeteilt. Jeder dieser 6-Bit-Blöcke bildet eine Zahl von 0 bis 63. Diese Zahlen werden anhand der nachfolgenden Umsetzungstabelle in „druckbare ASCII-Zeichen“ umgewandelt und ausgegeben. Der Name des Algorithmus erklärt sich durch ebendiesen Umstand – jedem Zeichen des kodierten Datenstroms lässt sich eine Zahl von 0 bis 63 zuordnen (siehe Tabelle). Mathematisch betrachtet gleicht dies einem Stellenwertsystem der Basis 64.
Padding
Falls die Gesamtanzahl der Eingabebytes nicht durch drei teilbar ist, beinhaltet der letzte Eingabeblock weniger als 24 Bits. In diesem Fall ist ein Padding der Eingabedaten erforderlich. An den Eingabeblock werden Nullbits angehängt, bis die Länge durch 6 teilbar ist. Anschließend wird die Ausgabe mit einem oder zwei = Zeichen aufgefüllt. Wenn der Eingabeblock 8 Bit lang ist, werden 4 Nullbits angehängt und zwei = Zeichen ausgegeben. Wenn der Eingabeblock 16 Bit lang ist, werden 2 Nullbits angehängt und ein = Zeichen ausgegeben.[1]
| Eingabebytes (Hex) |
Anzahl Bits |
aufgefüllt auf durch 6 teilbare Bitzahl (Binärdarstellung, Senkrechtstrich trennt Padding-Bits) |
Base64 (ohne Ausgabe-Padding) |
Base64 (mit Ausgabe-Padding) |
|---|---|---|---|---|
00 |
8 |
000000 00|0000 |
AA |
AA== |
00 00 |
16 |
000000 000000 0000|00 |
AAA |
AAA= |
00 00 00 |
24 |
000000 000000 000000 000000 |
AAAA |
AAAA |
FF |
8 |
111111 11|0000 |
/w |
/w== |
FF FF |
16 |
111111 111111 1111|00 |
//8 |
//8= |
FF FF FF |
24 |
111111 111111 111111 111111 |
//// |
//// |
Da sich die Anzahl der ursprünglichen Bytes immer eindeutig aus der Anzahl der Base64-Eingabe-Zeichen ermitteln lässt, wird in manchen Kontexten und Protokollen kein Padding verwendet (abweichend von der ursprünglichen Base64-Definition).
Platzbedarf
Bei einer zu kodierenden Eingabe mit Byte beträgt der Platzbedarf für den Base64-kodierten Inhalt (ohne Zeilenumbrüche) Zeichen. (Die Klammern um den Bruch stehen für die aufrundende Ganzzahldivision.)


In der Darstellung von sehr langen Base64-Strings werden diese oftmals (zum Beispiel nach jeweils 64 Zeichen) umgebrochen, also ein Zeilenumbruch eingefügt. Solche Zeilenumbrüche sind für die Dekodierung nicht von Belang und werden ignoriert.
Base64-Zeichensatz
| Wert | Zeichen | Wert | Zeichen | Wert | Zeichen | Wert | Zeichen | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dez. | binär | hex. | dez. | binär | hex. | dez. | binär | hex. | dez. | binär | hex. | |||||||
| 0 | 000000 |
00 | A | 16 | 010000 |
10 | Q | 32 | 100000 |
20 | g | 48 | 110000 |
30 | w | |||
| 1 | 000001 |
01 | B | 17 | 010001 |
11 | R | 33 | 100001 |
21 | h | 49 | 110001 |
31 | x | |||
| 2 | 000010 |
02 | C | 18 | 010010 |
12 | S | 34 | 100010 |
22 | i | 50 | 110010 |
32 | y | |||
| 3 | 000011 |
03 | D | 19 | 010011 |
13 | T | 35 | 100011 |
23 | j | 51 | 110011 |
33 | z | |||
| 4 | 000100 |
04 | E | 20 | 010100 |
14 | U | 36 | 100100 |
24 | k | 52 | 110100 |
34 | 0 | |||
| 5 | 000101 |
05 | F | 21 | 010101 |
15 | V | 37 | 100101 |
25 | l | 53 | 110101 |
35 | 1 | |||
| 6 | 000110 |
06 | G | 22 | 010110 |
16 | W | 38 | 100110 |
26 | m | 54 | 110110 |
36 | 2 | |||
| 7 | 000111 |
07 | H | 23 | 010111 |
17 | X | 39 | 100111 |
27 | n | 55 | 110111 |
37 | 3 | |||
| 8 | 001000 |
08 | I | 24 | 011000 |
18 | Y | 40 | 101000 |
28 | o | 56 | 111000 |
38 | 4 | |||
| 9 | 001001 |
09 | J | 25 | 011001 |
19 | Z | 41 | 101001 |
29 | p | 57 | 111001 |
39 | 5 | |||
| 10 | 001010 |
0A | K | 26 | 011010 |
1A | a | 42 | 101010 |
2A | q | 58 | 111010 |
3A | 6 | |||
| 11 | 001011 |
0B | L | 27 | 011011 |
1B | b | 43 | 101011 |
2B | r | 59 | 111011 |
3B | 7 | |||
| 12 | 001100 |
0C | M | 28 | 011100 |
1C | c | 44 | 101100 |
2C | s | 60 | 111100 |
3C | 8 | |||
| 13 | 001101 |
0D | N | 29 | 011101 |
1D | d | 45 | 101101 |
2D | t | 61 | 111101 |
3D | 9 | |||
| 14 | 001110 |
0E | O | 30 | 011110 |
1E | e | 46 | 101110 |
2E | u | 62 | 111110 |
3E | + | |||
| 15 | 001111 |
0F | P | 31 | 011111 |
1F | f | 47 | 101111 |
2F | v | 63 | 111111 |
3F | / | |||
In Dateinamen und URLs können die Zeichen +, / und = nicht verwendet werden, da sie dort für besondere Funktionen reserviert sind. In einem solchen Fall wird mit base64url eine inkompatible Abwandlung beschrieben. Die Zeichen + und / werden dann durch - (Minus, ASCII 2Dhex) und _ (Unterstrich, ASCII 5Fhex) ersetzt. Das Füllzeichen = am Ende wird prozentkodiert zu %3d, kann aber entfallen, wenn die Länge des Strings bekannt ist.[2]
Beispiel
Polyfon zwitschernd aßen Mäxchens Vögel Rüben, Joghurt und Quark
Dieser 64 Zeichen lange Text wäre in UTF-8-Kodierung 68 Byte lang, da in UTF-8 das Eszett und die Umlaute jeweils eine Länge von zwei Bytes haben. Mit der Umwandlung zu Base64 wird daraus eine 92 Zeichen lange Base64-Zeichenkette:
UG9seWZvbiB6d2l0c2NoZXJuZCBhw59lbiBNw6R4Y2hlbnMgVsO2Z2VsIFLDvGJl biwgSm9naHVydCB1bmQgUXVhcms=
Erkennbar ist hierbei, dass Base64 eine für Menschen nicht lesbare Kodierung erstellt. Dieser Umstand ist jedoch nicht als wirksame Verschlüsselung anzusehen, da der Datenstrom der Eingabe sehr leicht aus der Zeichenfolge am Ausgang zurückgewonnen werden kann, sobald diese als Base64-kodiert erkannt ist.
| Phase | Daten | Anmerkungen | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ursprungstext | Pol | ||||||||||||
| Unicode-Zeichen | U+0050 | U+006F | U+006C | gemäß Unicodeblock Basis-Lateinisch | |||||||||
| Bytes | 0x50 | 0x6F | 0x6C | gemäß UTF-8 | |||||||||
| Binärschreibweise | 0101 0000 | 0110 1111 | 0110 1100 | siehe Hexadezimalsystem | |||||||||
| Gruppierung in 6er-Blöcken | 010100 | 000110 | 111101 | 101100 | jeder 6er-Block entspricht einem Base64-Zeichen | ||||||||
| Codierung als Base64-Zeichen | U | G | 9 | s | gemäß der Tabelle oben von „binär“ nach „Zeichen“ | ||||||||
| Ohne Leerzeichen | UG9s | ||||||||||||
Radix-64
Das OpenPGP-Datenformat definiert eine Variante von Base64, die ASCII Armor genannt wird. Diese besteht aus genormten Kopf- und Fußzeilen, welche zum einen den Anfang und das Ende der Daten anzeigen, zum anderen einen Hinweis für den menschlichen Leser geben, welche Art von Daten kodiert ist und mit welchem Programm die Daten erzeugt worden sind.
An die Base64-kodierten Daten wird eine Prüfsumme (CRC-24) angehängt; dieses leicht modifizierte Verfahren trägt den Namen Radix-64.
-----BEGIN PGP MESSAGE----- Version: GnuPG v1.4.10 (GNU/Linux) jA0EAwMCxamDRMfOGV5gyZPnyX1BBPOQAE4BHbh7PfTDInn+94hXmnBr9D8+4x5R kNNl4E499Me3Fotq8/zvznEycz2h7vJ21SdP5akLhRPd4W1S79LoCvbZYh2x4t6x Cnqev6S97ys4chOPgz0FePfKQos0I7+rrMSAc9+vXHmUCthFqp7FJJ7/D9bCfmdF 1qkYNhtk/P5uvZ0N2zAUsiScDJA= =XXuR -----END PGP MESSAGE-----
Der Base64-Teil in diesem Beispiel beginnt mit jA0E… und endet mit …DJA=. Anschließend folgt ein Zeilenumbruch, ein Gleichheitszeichen und die Base64-kodierte CRC-24-Prüfsumme über die Original-Nachricht (also vor der Base64-Kodierung).
Siehe auch
Normen und Standards
- J. Linn: RFC – Privacy Enhancement for Internet Electronic Mail: Part I: Message Encryption and Authentication Procedures. Februar 1993 (löst ab, historisch, englisch).
- N. Borenstein, N. Freed: RFC – MIME (Multipurpose Internet Mail Extensions) Part One: Mechanisms for Specifying and Describing the Format of Internet Message Bodies. September 1993 – Standard: [draft] (löst ab, aktualisiert durch , veraltet, englisch).
- S. Josefsson: RFC – The Base16, Base32, and Base64 Data Encodings [Errata: RFC 3548]. Juli 2003 (aktualisiert durch , veraltet, abgelöst durch RFC 4648, englisch).
- S. Josefsson: RFC – The Base16, Base32, and Base64 Data Encodings [Errata: RFC 4648]. Oktober 2006 – Standard: [proposed] (löst ab, englisch).
- J. Callas, L. Donnerhacke, H. Finney, D. Shaw, R. Thayer: RFC – OpenPGP Message Format [Errata: RFC 4880]. November 2007 – Standard: [proposed] (aktualisiert durch , löst RFC 1991 und RFC 2440 ab, englisch).
Weblinks
Base64-Codierung/Decodierung online. base64decode.tech