Advanced Vector Extensions
Advanced Vector Extensions (AVX) ist eine Erweiterung des Befehlssatzes für Mikroprozessoren der x86-Architektur, die von Intel im März 2008 vorgeschlagen wurde.[1] AVX ist eine Erweiterung der älteren SIMD-Befehlssatzerweiterung Streaming SIMD Extensions 4, die ebenfalls von Intel initiiert wurde. Die Breite der Register und Datenwörter erhöht sich auf 256 Bit. Die folgende Tabelle zeigt die Weiterentwicklung der SIMD-Instruktionen in der x86-Architektur:
| Name der Erweiterung | Daten- breite | Registeranzahl | Adressierungs- schema | vorhanden in CPUs von | |
|---|---|---|---|---|---|
| Intel | AMD | ||||
| MMX / 3DNow! | 64 | 8 (MM0…7) | MMX ab Pentium (P55C) | K6 (MMX) / K6-2 „Chomper“ (3DNow!) | |
| SSE (1…4.*) | 128 | 8/16 (XMM0…15) | REX | SSE4: Core 2, Nehalem | K7 „Palomino“, K8, K8 „Venice“ |
| AVX | 256 | 16 (YMM0…15) | VEX | Sandy Bridge, Ivy Bridge | Bulldozer, Piledriver, Steamroller, Jaguar |
| AVX2 | Haswell, Broadwell, Skylake-i, Kaby Lake-i | Excavator, Zen, Zen 2, Zen 3 | |||
| AVX-512 | 512 | 32 (ZMM0…31) | EVEX | Skylake-X, Xeon Phi x200, Xeon Skylake-Scalable Processors, Tiger Lake | |
| 256/512 | Zen 4 | ||||
| AVX10.1 | 128/256/512 | 32 (ZMM0…31) | EVEX / REX2 | ||
| AVX10.2 | 128/256/512 | 32 (ZMM0…31) | EVEX / REX2 | ||
AVX2 erweitert den Befehlssatz von AVX um weitere 256-Bit-Befehle und wurde erstmals von Prozessoren der Haswell-Architektur (Intel) und Excavator-Architektur (AMD) unterstützt.
AVX-512 wurde 2013 veröffentlicht und erweiterte die AVX-Befehle von 256 auf 512 Bit.[2] Es wurde erstmals von Prozessoren der Knights-Landing-Architektur (Intel) unterstützt.
Als Intel APX für Advanced Performance Extensions überarbeitet Intel die bestehenden AVX-Befehlssatzerweiterungen, sodass auch bestehende Software durch Neukompilierung von den doppelt so vielen Registern (32 bei AVX-512 statt 16 bei SSE/AVX/AVX2) profitieren sollen. Der Name der auf AVX-512 aufbauenden Weiterentwicklung wird in AVX10 geändert, die vielen unterschiedlichen Erweiterungen für Server und Client vereinheitlicht und das Featureset dazu jeweils eingefroren. AVX10.1 soll bei den kommenden Intel Xeon „Scalable Processors“ der 5. Generation „Granite Rapids“ eingeführt werden. Spätere E- und P-Kerne sollen dann AVX10.2 erhalten. Mit AVX10 wird auch eine optionale variable Vektorlänge von 128, 256 und 512 Bit möglich; Zen-4-Prozessoren von AMD, die erstmals AVX-512 implementieren, unterstützen bereits zusätzlich eine Vektorlänge von 256 Bits.[3]
Neue Eigenschaften
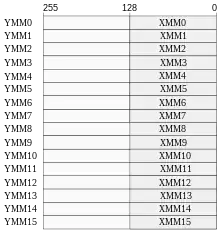
Die Breite der SIMD-Register wurde von 128 Bit (bei SSE) auf 256 Bit vergrößert. Die neuen notwendigen Register heißen YMM0 bis YMM15. Die Prozessoren, die AVX unterstützen, führen die älteren SSE-Befehle auf den unteren 128 Bit der neuen Register aus, d. h. die unteren 128 Bit der YMM-Register werden mit den XMM-Registern geteilt.
AVX führt ein Drei-Operanden-SIMD-Befehlsformat c := a + b ein, das Ergebnis zerstört damit nicht mehr notwendigerweise ein Quellregister, was Kopieroperationen einspart. SSE-Befehle nutzen die Zwei-Operanden-Form a := a + b. Das Drei-Operanden-Format kann nur mit SIMD-Operanden (YMM) verwendet werden und nicht mit Allzweckregistern, wie z. B. EAX oder RAX.
Anwendung
- Nützlich für gleitkommaintensive Berechnung, vor allem im Multimedia-, wissenschaftlichen oder Finanzbereich. Ganzzahloperationen folgten 2013.
- Erhöht Parallelität und Durchsatz von Gleitkomma- und Ganzzahl-SIMD-Berechnungen.
- Verringert die Registerlast durch nicht destruktive Drei-Operanden-Form.
Unterstützung in Compilern und Assemblern
GCC ab Version 4.6, die Intel Compiler Suite ab Version 11.1 und Visual Studio 2010 unterstützen AVX. Der GNU Assembler unterstützt AVX über Inline-Assemblerbefehle, ebenso wie Intels Pendant. Außerdem unterstützen MASM in der Version für Visual Studio 2010, Yasm ab Version 1.1.0, FASM und NASM nach eigenen Angaben auch AVX. Im x86-Codegenerator des Compiler-Unterbaus LLVM befindet sich eine vollständige AVX 1-Unterstützung ab Version 3.0.
Betriebssystemunterstützung
AVX braucht explizite Unterstützung durch das Betriebssystem, damit die neuen Register bei einem Kontextwechsel korrekt gespeichert und wiederhergestellt werden. Die folgenden Betriebssystemversionen unterstützen AVX:
- DragonFly BSD
- Anfang 2013[4]
- FreeBSD
- 9.1 vom 13. November 2013[5] durch einen am 21. Januar 2012 eingereichten Patch[6]
- Linux
- ab Kernel 2.6.30[7] vom 9. Juni 2009[8]
- macOS
- ab 10.6.8 (letztes Snow Leopard Update)[9] vom 23. Juni 2011
- OpenBSD
- 5.8 vom 18. Oktober 2015[10]
- Solaris
- 10 Update 10 und Solaris 11
- Windows
- ab Windows 7 SP1 und Windows Server 2008 R2 SP1 vom 22. Februar 2011[11]
CPUs mit AVX
- Sandy-Bridge-Prozessoren, Q1 2011[12]
- Ivy-Bridge-Prozessoren, Q2 2012
- Haswell-Prozessoren, Q2 2013
- Broadwell-Prozessoren, Q1 2015
- Skylake-Prozessoren, Q3 2015
- Kaby-Lake-Prozessoren, Q3 2016
- Coffee-Lake-Prozessoren Q4 2017
CPUs mit AVX-512
- Intel
- Cascade Lake
- Ice Lake: Jeder P-Kern (Performance-Kern) hat nur zwei AVX2-Einheiten, die für AVX512 zu einer AVX512-Einheit zusammengeschaltet werden, sodass sich gegenüber AVX2, abgesehen von den erweiterten Instruktionen, keine Leistungssteigerung erzielen lässt. Die E-Kerne (Effizienz-Kerne) verfügen über keine AVX512-Einheit.[15]
- Tiger Lake: Jeder P-Kern hat nur zwei AVX2-Einheiten, die für AVX512 zu einer AVX512-Einheit zusammengeschaltet werden, sodass sich gegenüber AVX2, abgesehen von den erweiterten Instruktionen, keine Leistungssteigerung erzielen lässt. Die E-Kerne verfügen über keine AVX512-Einheit.[16]
- Alder Lake: Nur in frühen CPU-Steppings nutzbar, AVX512 nicht offiziell unterstützt, ausschließlich in den P-Kernen implementiert. Zuerst von Intel über BIOS und Microcode-Updates deaktiviert, in späteren Steppings komplett in Hardware deaktiviert.
- AMD
- Zen 4
- Ryzen 7000 „Raphael“[17]
- EPYC 9000 „Genoa“ (angekündigt)[18]
Neue Instruktionen AVX
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
| Instruktion | Beschreibung |
|---|---|
| VBROADCASTSS VBROADCASTSD VBROADCASTF128 |
Kopiert einen 32-Bit-, 64-Bit- oder 128-Bit-Speicheroperanden in alle Elemente eines XMM- oder YMM-Registers. |
| VINSERTF128 | Ersetzt entweder die obere oder untere Hälfte eines 256-Bit-YMM-Register mit dem Wert aus dem 128-Bit-Operanden. Die andere Hälfte bleibt unverändert. |
| VEXTRACTF128 | Extrahiert entweder die obere oder untere Hälfte eines 256-Bit-YMM-Registers und kopiert den Wert in den 128-Bit-Operanden. |
| VMASKMOVPS VMASKMOVPD |
Liest eine beliebige Anzahl von Vektorelementen bedingt aus einem SIMD-Speicheroperand in ein Zielregister, wobei der verbleibende Platz mit Nullen gefüllt wird. Alternativ schreibt es eine beliebige Anzahl von Vektorelementen bedingt von einem SIMD-Register in ein SIMD-Speicheroperanden, wobei der verbleibende Platz im Speicher nicht verändert wird. |
| VPERMILPS VPERMILPD |
Tauscht 32-Bit- oder 64-Bit-Vektorelemente aus. |
| VPERM2F128 | Mischt die vier 128-Bit-Vektorelemente aus zwei 256-Bit-Ursprungsoperanden in ein 256-Bit-Zieloperanden. |
| VTESTPS, VTESTPD | Setzt die Flag-Bits CF und ZF entsprechend einem Vergleich aller Vorzeichenbits. |
| VZEROALL | Füllt alle YMM-Register mit Nullen und markiert sie als unbenutzt. Wird beim Umschalten zwischen 128-Bit- und 256-Bit-Modus verwendet. |
| VZEROUPPER | Füllt die obere Hälfte aller YMM-Register mit Nullen. Wird beim Umschalten zwischen 128-Bit- und 256-Bit-Modus verwendet. |
Erweiterung AVX 2
Eine Erweiterung stellen die Advanced Vector Extensions 2 (AVX2) dar, bei der einige neue Instruktionen eingeführt wurden und zahlreiche bestehende Instruktionen nun ebenfalls 256 Bit breit sind. AVX2 wird erstmals mit den AMD Carrizo bzw. Intel Haswell-Prozessoren vertrieben.
Erweiterung AVX-512
Da im High-Performance-Computing (HPC) mittlerweile die Energieeffizienz immer wichtiger wird und das SIMD-Konzept hier Fortschritte verspricht, wurde für die Intel Xeon Phi genannten Rechenbeschleunigerkarten die Befehlssatzerweiterung AVX2 nochmals komplett überarbeitet. Unter anderem wurde hierbei die Daten- und Registerbreite auf 512 Bit verdoppelt sowie die Anzahl der Register auf 32 verdoppelt. Diese überarbeitete Erweiterung nennt Intel AVX-512, sie besteht aus mehreren spezifizierten Gruppen neuer Instruktionen, welche gestaffelt implementiert werden. Die zweite Xeon Phi-Generation (Knights Corner) erhält die sogenannte Foundation, die dritte Generation (Knights Landing, 2016) zusätzlich die CD-, PF- und ER-Erweiterungen.
Im Unterschied zu Xeon Phi einschließlich Knights Landing sind die Befehlsgruppen DQ, BW und VL Bestandteil der im Sommer 2017 erschienen Xeon Scalable Processors und der von ihnen abgeleiteten Skylake-X-Prozessoren (ab Core i7-7800X).
Die Befehlsgruppen wurden von Intel bereits vorab dokumentiert und sind über die CPUID-Instruktion abfragbar, bestimmte Register-Bits sind bei Vorhandensein der Befehlsgruppe gesetzt. Bei AMD Zen 4 ist AVX-512 „double-pumped“ durch zwei 256-Bit-Voktoreinheiten,[19] die Leistung ist jedoch „erstaunlich gut“.[20] Bei Intel ist AVX-512 als Spezifikation beziehungsweise Roadmap zu sehen, welche Instruktionen Intel zukünftig in die AVX-Einheiten bringen will[21] :
| Befehlssatz | Name Set | CPUID-Bit | Prozessoren | |
|---|---|---|---|---|
| Intel | AMD | |||
| AVX512F (Basisbefehlssatz, restliche Befehle sind optional) | Foundation | EBX 16 | Xeon Phi x200, Xeon SP | Zen 4 |
| AVX512PF | Prefetch | EBX 26 | Xeon Phi x200 | |
| AVX512DQ | Vector Double Word and Quad Word | EBX 17 | Xeon SP | Zen 4 |
| AVX512BW | Vector Byte and Word | EBX 30 | Xeon SP | Zen 4 |
| AVX512VL | Vector Length | EBX 31 | Xeon SP | Zen 4 |
| AVX512CD | Conflict Detection | EBX 28 | Xeon Phi x200, Xeon SP | Zen 4 |
| AVX512ER | Exponential and Reciprocal | EBX 27 | Xeon Phi x200 | |
| AVX512IFMA | Integer Fused Multiply-Add mit 512 Bit | EBX 21 | Cannon Lake | Zen 4 |
| AVX512_VBMI | Vector Bit Manipulation | ECX 01 | Cannon Lake | Zen 4 |
| AVX512_VBMI2 | Vector Bit Manipulation 2 | ECX 06 | Cannon Lake | Zen 4 |
| AVX512_4FMAPS | Vector Fused Multiply Accumulation Packed Single precision | EDX 03 | Xeon Phi 72x5 | |
| AVX512_4VNNIW | Vector Neural Network Instructions Word Variable Precision | EDX 02 | Xeon Phi 72x5 | |
| AVX512_VPOPCNTDQ | Vector POPCOUNT Dword/Qword | ECX 14 | Xeon Phi 72x5 | Zen 4 |
| AVX512_VNNI | Vector Neural Network Instructions | ECX 11 | Xeon Cascade Lake | Zen 4 |
| AVX512_BITALG | Bitalgorithmen, Support for VPOPCNT[B,W] and VPSHUF-BITQMB | ECX 12 | Ice Lake | Zen 4 |
| AVX512_GFNI | Galois Field New Instructions | Ice Lake | ||
| AVX512_VPCLMULQDQ | Carry-Less Multiplication Quadword | Ice Lake | ||
| AVX512_VAES | Vector AES | Ice Lake | ||
| AVX512_BF16 | BFLOAT16 Floating-Point Format | Cooper Lake, Sapphire Rapids | Zen 4 | |
Implementierung der einzelnen Befehlsgruppen dokumentiert für Xeon SP[22] und für Xeon Phi Knights Landing (x200).[23]
Benutzung
Die Benutzung dieser Spezialbefehle läuft auf folgendes hinaus:
- Isolation der zu optimierenden Programmteile, nur diese müssen überhaupt betrachtet werden
- zu optimieren sind dort:
- Speicherlayout der verwendeten Datenstrukturen (Alignment, Cache-Effizienz, Lokalität von Speicherzugriffen)
- Zerlegungen der Berechnungen in viele unabhängige Threads, die parallel und z. T. auf verschiedenen Architekturen abgearbeitet werden können (z. B. auf eine/mehrere GPU(s) ausgelagert werden können)
- Nutzen dieser erweiterten Befehlssätze durch …
- Nutzung von Compilern, die diese Befehlssätze unterstützen
- Nutzung von Bibliotheken, die diese Befehlssätze nutzen (z. B. Math Kernel Library oder OpenBLAS)
- Nutzung von Bibliotheken, die wiederum solche Bibliotheken nutzen (z. B. Graphikbibliotheken)
- Nutzung von Programmiersprachen, die von sich aus Gebrauch von diesen Befehlen machen (z. B. Python mit dem numpy-Paket)
- Bei sehr kritischen Applikation kann das Nutzen von Compiler Intrinsics oder das Schreiben von Assembler-Routinen zu einer weiteren Performance-Steigerung notwendig sein.
Die Probleme sind aber nicht neu und das Nutzen der Befehlssatzerweiterungen ist von diesen Optimierungen noch der Teil, der sich am besten automatisieren lässt.
Fazit
Programme können mithilfe von AVX und dessen 256 Bit breiten Registern im x64-Modus in jedem Taktzyklus vier Gleitkommaoperationen mit doppelter Genauigkeit oder acht Gleitkommaoperationen mit einfacher Genauigkeit bei bspw. einer einfachen Addition berechnen. Dabei befinden sich jeweils vier Werte doppelter Genauigkeit oder acht Werte einfacher Genauigkeit in jeweils einem der 16 AVX-Register, die dann mit jeweils einem Partner verrechnet werden.
Mit AVX2 verändert sich die Registerbreite nicht, es wurden lediglich einige der zuvor (bei AVX) noch mit 128 Bit ausgeführten Operationen (z. B. FMA3: Fused-Multiply Add/Floating-Point Multiply-Accumulate, Integeroperationen…) auf 256 Bit-Ausführung gebracht.[24] Es ändert sich somit die Anzahl der verfügbaren 256-Bit-SIMD-Operationen. Bei einer einfachen Addition auf einer 64-Bit-Architektur werden weiterhin (nur) vier Gleitkommaoperationen mit doppelter Genauigkeit oder acht Gleitkommaoperationen mit einfacher Genauigkeit gleichzeitig berechnet.
Bei AVX-512 sind es aufgrund der Registerbreite von 512 Bit damit pro Befehl acht Additionen in doppelter Genauigkeit oder 16 Additionen in einfacher Genauigkeit. Die Nutzung von AVX-512 beschränkt sich im Desktop-Segment gegenwärtig (2018) auf den X299-Chipsatz der Skylake-Architektur für den Sockel 2066 sowie seit 2016 auch auf eine Reihe der Xeon-Prozessorbaureihen.
Mit der auf AVX-512 aufbauenden Weiterentwicklung APX (Advanced Performance Extensions), später in AVX10 umbenannt, verdoppelt sich die Anzahl der 512 Bit breiten Register auf 32 pro physischem CPU-Kern.
Einzelnachweise
- Thomas Hübner: SSE-Nachfolger heißt AVX und ist 256 Bit breit. ComputerBase, 17. März 2008, abgerufen am 29. März 2018.
- James Reinders: AVX-512 Instructions. Intel, 23. Juli 2013, abgerufen am 15. Dezember 2022 (englisch).
- Carsten Spille: Intel APX: Effizienter und schneller mit neuer x86-Befehlssatzerweiterung AVX10. In: Heise online. 25. Juli 2023. Abgerufen am 30. Juli 2023.
- x86_64 – support for AVX instructions. Abgerufen am 20. November 2013.
- FreeBSD 9.1-RELEASE Announcement. Abgerufen am 20. Mai 2013.
- Add support for the extended FPU states on amd64, both for native 64bit and 32bit ABIs. svnweb.freebsd.org, 21. Januar 2012, abgerufen am 22. Januar 2012.
- x86: add linux kernel support for YMM state. Abgerufen am 13. Juli 2009.
- Linux 2.6.30 – Linux Kernel Newbies. Abgerufen am 13. Juli 2009.
- Twitter. Abgerufen am 23. Juni 2010.
- Theo de Raadt: OpenBSD 5.8. Abgerufen am 7. Dezember 2015.
- Floating-Point Support for 64-Bit Drivers. Abgerufen am 6. Dezember 2009.
- Intel Offers Peek at Nehalem and Larrabee. ExtremeTech, 17. März 2008, abgerufen am 20. August 2011.
- Bulldozer Roadmap. Joe Doe, AMD Developer blogs, 7. Mai 2009, abgerufen am 8. September 2011.
- AMD Piledriver vs. Steamroller vs. Excavator – Leistungsvergleich der Architekturen. In: Planet 3DNow! 14. August 2015, archiviert vom (nicht mehr online verfügbar) am 21. Februar 2017; abgerufen am 20. Februar 2017.
- https://cdrdv2-public.intel.com/671488/248966-Software-Optimization-Manual-R047.pdf
- https://cdrdv2-public.intel.com/671488/248966-Software-Optimization-Manual-R047.pdf
- AMD Ryzen 7000: Up to 16 Cores, AVX-512 Support at Launch auf tomshardware.com vom 27. Mai 2022.
- AMD Zen 4: Epyc-Prozessoren mit 96 CPU-Kernen und AVX-512 auf heise.de vom 17. August 2021.
- https://www.phoronix.com/review/amd-zen4-avx512
- https://www.tomshardware.com/news/avx-512-performance-impresses-on-ryzen-7040
- ISA-Extensions Programming Reference. Abgerufen am 17. Oktober 2017.
- Xeon SP Technical Overview. Abgerufen am 17. Oktober 2017.
- How to detect KNL instruction support. Abgerufen am 17. Oktober 2017.
- Gepner, Pawel. "Using AVX2 instruction set to increase performance of high performance computing code", Computing and Informatics 36.5 (2017): 1001-1018.