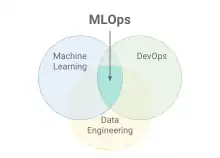
MLOps — парадыгма распрацоўкі праграмнага забеспячэння, накіраваная на надзейнае і эфектыўнае разгортванне і падтрыманне мадэлей машыннага навучання для практычнага выкарыстання. Слова з’яўляецца спалучэннем «машыннага навучання» (англ.: Machine Learning, ML) і практыкі распрацоўкі DevOps.
MLOs пачынаўся як набор перадавых практык, і цяпер паступова ператвараецца ў незалежны падыход да кіравання жыццёвым цыклам сістэм машыннага навучання. MLOps прымяняецца на ўсіх этапах жыццёвага цыкла — ад распрацоўкі да аркестроўкі, разгортвання і маніторынгу мадэлей.
Гісторыя
У пачатку 2000-х для распрацоўкі бізнес-рашэнняў на базе машыннага навучання выкарыстоўвалася такое прапрыетарнае праграмнае забеспячэнне як SAS, SPSS і FICO. З пашырэннем адкрытага праграмнага забеспячэння, усё больш распрацоўшчыкаў пачалі выкарыстоўваць бібліятэкі Python і R для трэніроўкі мадэлей. Для разгортвання мадэлей з мэтай іх практычнага выкарыстання ужываліся такія інструменты як Docker і Kubernetes. З цягам часу паўсталі так званыя MLOps-платформы, якія пакрываюць увесь цыкл эксперыментавання, трэніроўкі, разгортвання і маніторынгу мадэлей[2].
Рост папулярнасці MLOps абумоўлены патрэбнасцю ў стандартызацыі працэсаў распрацоўкі машыннага навучання. Рынак MLOps-інструментаў ацэньваўся ў $1.1 млрд у 2022 годзе, з прагнозам росту да $5.9 млрд да 2027 года, то бок у сярэднім на 41 % штогод[3].
Параўнанне з DevOps
Асаблівасць сістэм з машынным навучаннем заключаецца ў наяўнасці трох узаемазвязаных кампанентаў: даных, мадэлі машыннага навучання і кода[2]. Пры распрацоўцы звычайнага праграмнага забеспячэння мадэль, а часам і даныя адсутнічаюць.
Акрамя таго, існуе шэраг характэрных праблем, якія ўплываюць на працэс распрацоўкі рашэнняў з машынным навучаннем[2]:
- Паступовае зніжэнне якасці мадэлі пасля разгортвання, што выклікае неабходнасць у зборы найноўшых даных і ператрэніроўцы мадэлі.
- Недастатковасць даных для развязання пастаўленай задачы.
- Неадпаведнасць даных для трэніроўкі тым даным, з якімі мадэль мусіць працаваць пасля разгортвання. Напрыклад, калі мадэль прымяняецца ў тым рэгіёне, даныя з якога не ўваходзілі ў трэніровачны набор.
- Збор новых або абнаўленне разметкі ў старых даных, што патрабуе ператрэніроўкі мадэлі.
- Некарэктнасць дапушчэнняў, зробленых на этапе стварэння мадэлі.
- Змена патрабаванняў да мадэлі ў часе распрацоўкі.
Неабходнасць вырашэння гэтых праблем адрознівае MLOps ад звычайных DevOps-працэсаў.
Асноўныя прынцыпы
Пашырэнне прадуктаў і сэрвісаў з машынным навучаннем прывяло да неабходнасці стварэння практык эфектыўнага тэсціравання, разгортвання, кіравання і маніторынгу такіх сістэм для змяншэння іх тэхнічнага доўгу[4]. MLOps імкнецца да таго, каб рэсурсы, звязаныя з машынным навучаннем (мадэль, яе параметры і гіперпараметры, код для навучання мадэлі, даныя для навучання і тэсціравання), разглядаліся нароўні з іншымі рэсурсамі ў CI/CD асяроддзі, а мадэлі машыннага навучання разгортваліся ў рамках уніфікаванага працэсу разам з сэрвісамі, што іх выкарыстоўваюць і забяспечваюць выкарыстанне[5].
Аўтаматызацыя
Аўтаматызаванымі могуць быць такія працэсы, як напрыклад навучанне, тэсціраванне і разгортванне мадэлі. Аўтаматызацыя паскарае распрацоўку мадэлі, а аўтаматызаванае тэсціраванне дазваляе хутка і своечасова знаходзіць і вырашаць праблемы. Аўтаматычнае навучанне і разгортванне мадэлі могуць быць выкліканы рэгулярна па раскладзе або ў выніку пэўных падзей, напрыклад змяншэння якасці мадэлі да крытычнага значэння ці змены кода мадэлі[4].
Існуюць наступныя ўзроўні аўтаматызацыі[4]:
- Ручны працэс. Поўная адсутнасць аўтаматызацыі, характэрная для першых, эксперыментальных этапаў распрацоўкі. Часта выкарыстоўваюцца інструменты для хуткай распрацоўкі, такія як Jupyter Notebooks.
- Пайплайн машыннага навучання. Аўтаматызавана навучанне мадэлі ў выпадку з’яўлення новых даных. Сюды ж уваходзяць аўтаматычная валідацыя даных і мадэлі.
- CI/CD пайплайн. Існуе CI/CD працэс для разгортвання мадэлі машыннага навучання ў production-асяроддзі. Аўтаматызавана зборка, тэсціраванне і разгортванне ўсіх кампанентаў сістэмы.
Бесперапыннасць
Шэраг прынцыпаў бесперапыннасці забяспечвае стабільнасць і даступнасць для выкарыстання мадэлі, кода і даных[4]:
- Бесперапынная інтэграцыя (англ.: Continuous Integration, CI) — тэсціраванне і валідацыя, што пашыраецца не толькі на код, але і на мадэль і даныя.
- Бесперапынная дастаўка (англ.: Continuous Delivery, CD) — стварэнне пайплайна навучання мадэлі, які аўтаматычна разгортвае сэрвіс для прадказвання.
- Бесперапыннае навучанне (англ.: Continuous Training, CT) — аўтаматычнае рэгулярнае навучанне мадэлей для разгортвання.
- Бесперапынны маніторынг (англ.: Continuous Monitoring, CM) — кантроль за данымі і вынікамі працы мадэлі ў production-асяроддзі, у тым ліку падлік бізнес-метрык.
Кантроль версій
Акрамя стандартнага кантролю версій для кода, MLOps прадугледжвае аналагічнае версіянаванне для мадэлей і даных. Гэта абумоўлена тым, што як даныя, так і мадэль змяняюцца з часам пад уплывам розных фактараў, напрыклад абнаўлення крыніц даных і паўторнага навучання мадэлі. Кантроль версій дапамагае хутка адкаціць мадэль або даныя да папярэдняй версіі, калі абнаўленне прынесла непажаданыя вынікі. Захоўванне ўсіх версій мадэлі і даных можа таксама быць патрабаваннем з боку кампаніі або дзяржавы для таго, каб сістэму можна было праверыць на адпаведнасць заканадаўству і іншым стандартам[4].
Улік эксперыментаў
У адрозненне ад класічнага праграмнага забеспячэння, машыннае навучанне патрабуе вялікай колькасці эксперыментаў каб зразумець, якую мадэль лепей выкарыстоўваць. Вядзенне ўліку эксперыментаў дазваляе пабачыць, з якімі параметрамі пэўны эксперымент запускаўся і як ён паўплываў на якасць мадэлі, а таксама правесці параўнанне паміж вынікамі вялікай колькасці эксперыментаў. Адзін з падыходаў да ўліку — стварэнне асобнай git-галіны для кожнага эксперыменту. Існуюць таксама інструменты для аўтаматычнага запісу гіперпараметраў і метрык для ўсіх эксперыментаў, напрыклад Weights & Biases[4].
Тэсціраванне
Тэсціраванне сістэм з машынным навучаннем складаецца з трох кампанентаў: тэсціраванне даных, мадэлі і інфраструктуры[4].
Тэсціраванне даных уключае этапы валідацыі даных (аўтаматызаваная праверка на адпаведнасць структуры), падліку важнасці прыкмет для адсейвання неістотных даных, праверку на адпаведнасць рэгуляцыям, такім як GDPR. Сюды ж уваходзіць юніт-тэсціраванне кода для падліку прыкмет[4].
Для тэсціравання мадэлі ацэньваецца яе якасць з дапамогай адмысловых метрык (сярэднеквадратычная памылка, лагістычная памылка і г.д.), якія павінны мець карэляцыю з бізнес-метрыкамі (прыбытак, зацікаўленасць карыстальнікаў і г.д.) Такія метрыкі падлічваюць на адкладзеным наборы даных для тэсціравання, што не выкарыстоўваецца ў часе навучання мадэлі. Складаныя мадэлі мусяць параўноўвацца з больш простай, так званай бэйзлайн-мадэллю. Напрыклад, няма рацыі ў выкарыстанні нейроннай сеткі, калі лінейная рэгрэсія паказвае нягоршыя вынікі для пэўнай задачы. Акрамя таго, правяраецца сумленнасць мадэлі, то бок яе карэктная праца для розных катэгорый карыстальнікаў. Для параўнання розных версій мадэлі можа прымяняцца A/B-тэсціраванне[4].
Тэсты для інфраструктуры правяраюць такія ўласцівасці як дэтэрмінаванасць навучання (навучанне з аднолькавымі наборамі даных павінна даваць аднолькавыя параметры мадэлі), памяншэнне значэння функцыі страт у ходзе навучання, адпаведнасць памылкі ў асяроддзі навучання памылцы ў production-асяроддзі. Існуюць таксама краш-тэсты, якія правяраюць аднаўленне стану мадэлі ў кантрольным пункце, калі ў працэсе навучання здарыўся збой. Інтэграцыйныя тэсты праганяюць увесь пайплайн цалкам і правяраюць, што кожны этап навучання завяршаецца паспяхова[4].
Маніторынг
Каб праверыць, ці працуе мадэль як запланавана пасля разгортвання, ажыццяўляецца яе маніторынг. Сістэма маніторынгу павінна паведамляць пра павольны або рэзкі спад якасці мадэлі. Пры атрыманні такога сігналу можа аўтаматычна запускацца перанавучанне і абнаўленне версіі мадэлі[4].
Акрамя гэтага, маніторынг можа закранаць змены ў даных і кодзе, абнаўленні ў залежнасцях, выхад значэнняў у даных за звычны дыяпазон, адпаведнасць прыкмет у працоўным і навучальным асяроддзях, вылічальную ўстойлівасць мадэлі (адсутнасць бесканечных і NaN-значэнняў у падліках), хуткасць падлікаў, выкарыстанне вылічальных рэсурсаў (памяць, месца на дыску, сеткавы трафік і інш.), час з апошняга абнаўлення мадэлі і гэтак далей[4].
Рабочы працэс MLOps
Распрацоўка праграмнага забеспячэння з машынным навучаннем уключае ў сябе такія этапы як аналіз задачы, інжынірынг даных, распрацоўка і інтэграцыя мадэлі.
Аналіз бізнес-задачы і патрабаванняў
Першапачатковы этап праекта па распрацоўцы праграмнага забеспячэння мае сваёй мэтай зразумець задачу і той працэс, у якім будзе выкарыстоўвацца гатовае рашэнне. У выпадку з машынным навучаннем, патрабаванні да рашэння мусяць быць перакладзены ў патрабаванні да мадэлі, яе структуры і якасці.
У пачатку такога аналізу пэўны бізнес-працэс разбіваецца на асобныя задачы. З гэтых задач вылучаюцца тыя, для выканання якіх патэнцыйна можа выкарыстоўвацца машыннае навучанне. Для кожнай задачы ацэньваецца акупнасць інвестыцый у яе аўтаматызацыю. Задачы з найбольшай акупнасцю разглядаюцца больш падрабязна[6].
Абмеркаванне дапамагае зразумець сапраўдныя мэты і магчымыя выдаткі. Адным з вынікаў гэтага этапу можа быць рашэнне не распрацоўваць мадэль машыннага навучання, напрыклад таму што працэс не дапускае некарэктных адказаў мадэлі, рашэнне будзе мець нізкую акупнасць, або сістэму не магчыма будзе падтрымліваць.
AI Canvas
Адзін з метадаў аналізу бізнес-задач з пункту гледжання машыннага навучання, AI Canvas, быў прапанаваны Аджаем Агравалам у кнізе «Машыны прагназавання. Простая эканоміка штучнага інтэлекту» (англ.: Prediction Machines. The Simple Economics of Artificial Intelligence). AI Canvas складаецца з сямі пытанняў, якія павінны дапамагчы ў прыняцці рашэння аб распрацоўцы[6][7]:
- Прадказанне. У чым заключаецца нявызначанасць, якую можна вырашыць з дапамогай машыннага навучання?
- Ацэнка. Як ацаніць эфект магчымых вынікаў, як станоўчых, так і памылковых?
- Дзеянне. Якія дзеянні могуць быць абраныя?
- Вынік. Як можна зразумець, што задача была выканана карэктна?
- Навучанне. Якія даныя патрэбны для навучання мадэлі?
- Уваход. Якія даныя патрэбны для таго, каб гатовая мадэль магла зрабіць прагноз?
- Зваротная сувязь. Як можна выкарыстаць вынікі для паляпшэння якасці мадэлі?
Напрыклад разгледзім праблему лжывых спрацоўванняў ахоўнай сігналізацыі. Калі доля лжывых спрацоўванняў высокая, шмат рэсурсаў паліцыі або аховы марнуецца. Пры разгляданні магчымасці вырашыць гэтую праблему з дапамогай машыннага навучання, адказы на пытанні AI Canvas могуць гучаць наступным чынам[7]:
- Прадказанне. Прадказаць, ці сапраўды за спрацоўваннем сігналізацыі стаіць пагроза.
- Ацэнка. Параўнаць кошт рэагавання на лжывае спрацоўванне сігналізацыі з коштам адсутнасці рэакцыі на сапраўднае спрацоўванне.
- Дзеянне. Выклікаць або не выклікаць ахову ў адказ на спрацоўванне.
- Вынік. Спраўдзіць, ці абранае дзеянне было слушным.
- Навучанне. Гістарычныя даныя датчыкаў і адпаведных ілжывых і карэктных спрацоўванняў сігналізацыі.
- Уваход. Даныя з датчыкаў у той момант, калі спрацавала сігналізацыя.
- Зваротная сувязь. Падзяліць новыя даныя з датчыкаў на дзве катэгорыі: ілжывыя і карэктныя спрацоўванні. Дадаць гэтыя даныя да гістарычных і абнавіць мадэль.
Machine Learning Canvas
Яшчэ адзін метад аналізу задачы — Machine Learning Canvas. Ён складаецца з дзесяці блокаў, кожны з якіх з дапамогай пытанняў дазваляе паглядзець на задачу з таго ці іншага боку[7].
Асноўны блок — значная прапанова. У межах гэтага блока разглядаюцца пытанні аб тым, у чым заключаецца праблема, чаму гэта важна і хто будзе канчатковым карыстальнікам рашэння. У выніку фармулюецца прапанова, у якой згадваецца праблема і прадукт або сэрвіс, які плануецца распрацаваць для яе рашэння.
Іншыя блокі бяруць пад увагу крыніцы даных, тып задачы (класіфікацыя, рэгрэсія, кластарызацыя і г.д.), прыкметы для мадэлі, ацэнку якасці, працэс прыняцця рашэнняў на аснове адказаў мадэлі, працэдуру выкарыстання мадэлі (на запыт, паводле раскладу і інш.), збор новых даных, абнаўленне і маніторынг мадэлі.
Інжынірынг даных
Асноўныя задачы інжынірынгу даных — збор і падрыхтоўка набору даных для далейшага навучання мадэлі. Гэты этап мае вялікае значэнне, бо недастатковая якасць даных можа прывесці да некарэктнай працы мадэлі. Залежнасць паміж якасцю даных і мадэлі апісваецца прынцыпам «смецце на ўваходзе, смецце на выхадзе» (англ.: Garbage In, Garbage Out). Звычайна даныя збіраюцца з некалькіх крыніц у розных фарматах. У працэсе падрыхтоўкі даных праводзіцца іх даследаванне, ачыстка, камбінаванне і трансфармацыя[8][9].
Інжынірынг даных падзяляецца на наступныя элементы:
- Прыём даных — збор неапрацаваных даных у розных фарматах. Можа таксама ўключаць генерацыю сінтэтычных даных і ўзбагачэнне даных.
- Даследаванне і валідацыя — прафіляванне даных, неабходнае для разумення іх структуры і зместу. Валідацыя можа праводзіцца з дапамогай функцый, якія правяраюць даныя на прадмет памылак і анамалій.
- Ачыстка і першасная апрацоўка даных — працэс выпраўлення памылак, выдалення выкідаў, запаўнення пропускаў у даных.
- Разметка даных — прысваенне элементам даных пэўных метак у залежнасці ад задачы, напрыклад аднясенне іх да той ці іншай катэгорыі.
- Падзел даных — раздзяленне даных на наборы для навучання, валідацыі і тэсціравання мадэлі.
Распрацоўка мадэлі
Распрацоўка мадэлі складаецца з некалькі этапаў, у выніку якіх ствараецца мадэль, гатовая да інтэграцыі[8]:
- Навучанне мадэлі — працэс прымянення алгарытму машыннага навучання да набору навучальных даных. Сюды ж уваходзяць стварэнне прыкмет для мадэлі і падбор гіперпараметраў.
- Ацэнка мадэлі — валідацыя мадэлі з падлікам метрык, што ацэньваюць якасць яе работы.
- Тэсціраванне мадэлі — фінальная праверка мадэлі на адкладзеным наборы даных.
- Пакетызацыя мадэлі — перавод мадэлі ў патрэбны для прымянення фармат (напрыклад PMML, PFA, ONNX і інш.)
Інтэграцыя мадэлі
Распрацаваная мадэль інтэгруецца ў гатовы прадукт, напрыклад мабільную або настольную праграму. Інтэграцыя ўключае ў сябе наступныя этапы[8]:
- Разгортванне мадэлі — прыстасаванне мадэлі да production-асяроддзя.
- Маніторынг мадэлі — назіранне за дзейнасцю і якасцю мадэлі ў працэсе яе выкарыстання. Вынікі маніторынгу могуць дапамагчы зразумець, калі патрабуецца паўторнае навучанне мадэлі на абноўленых даных.
- Лагаванне — запіс і захоўванне ўсіх запытаў да мадэлі.
Шаблоны архітэктуры
Архітэктура сістэмы машыннага навучання залежыць ад спосабу навучання і генерацыі прадказанняў мадэлі.
Існуюць два віды навучання[9]:
- Афлайнавае (навучанне батчамі, статычнае навучанне), пры якім мадэль навучаецца на загадзя сабраным наборы даных. Такая мадэль застаецца нязменнай пасля разгортвання, таму з часам можа страціць актуальнаць. Зніжэнне якасці можна адсачыць з дапамогай маніторынгу, і паўторна навучыць мадэль як толькі яно адбудзецца.
- Анлайнавае (дынамічнае) навучанне мае месца, калі працэс перанавучання запускаецца рэгулярна з прыходам новых данных, напрыклад у патоку.
Генерацыя прадказанняў таксама падзяляецца на два тыпы[9]:
- Прадказванне батчамі адбываецца раз на некаторы прамежак часу для сабраных за гэты час даных.
- Прадказванне ў рэальным часе праводзіцца тады, калі адказ мадэлі патрэбен у той самы момант, калі быў атрыманы запыт.
Камбінацыя відаў навучання і прадказвання вызначае архітэктуру сістэмы і ступень яе аўтаматызацыі.
Прагноз
Такі тып архітэктуры прадугледжвае аднаразовае навучанне мадэлі на гістарычных даных і генерацыю прагнозу на іншым, але таксама гістарычным наборы даных. Гэта самы просты тып архітэктуры, які выкарыстоўваецца ў даследаваннях і ў адукацыйных мэтах пры вывучэнні машыннага навучання, але яго часта бывае недастаткова для выкарыстання на практыцы[9].
Вэб-сэрвіс
Архітэктура вэб-сэрвісу (або мікрасэрвісу) гэта камбінацыя афлайнавага навучання з прадказваннем у рэальным часе. У гэтым падыходзе мадэль працуе з кожным запытам асобна, атрымлівае на ўваход даныя запыту і вяртае прадказанне для гэтага запыту на выхадзе. Пры гэтым сама мадэль не змяняецца да той пары, пакуль не будзе паўторна навучана і разгорнута. Архітэктура сэрвісу падзяляецца, адпаведна, на дзве часткі: навучанне і прадказванне. Артэфактам навучання выступае гатовая мадэль, якая на этапе прадказвання ўзаемадзейнічае з кліентам, напрыклад праз REST API[9].
Анлайнавае навучанне
У архітэктуры анлайнавага навучання мадэль абнаўляецца як толькі новыя даныя прыходзяць у сістэму. Звычайна даныя арганізаваны ў выглядзе патоку, які можа складацца з індывідуальных назіранняў або міні-батчаў (невялікіх груп). Як правіла, першаснае навучанне мадэлі праводзіцца на гістарычных даных асобна ад анлайн-сістэмы, у якой праходзіць толькі інкрэментнае паляпшэнне мадэлі з дапамогай новых даных. Мадэль можа быць разгорнута як сэрвіс на Kubernetes кластары або падобным чынам[9].
Загана анлайнавага навучання ў тым, што якасць мадэлі можа хутка сапсавацца, калі ў сістэму будуць прыходзіць няякасныя даныя[9].
Серыялізацыя мадэлі
Часта бывае так, што навучанне і выкарыстанне мадэлі машыннага навучання адбываюцца ў розных асяроддзях. Напрыклад, калі мадэль, навучаную з дапамогай бібліятэкі scikit-learn трэба запусціць у выглядзе Spark задачы. У такіх выпадках мадэль пераводзіцца ў адзін з адмысловых фарматаў, прыгодных для распаўсюджання. Фарматы серыялізацыі бываюць як універсальнымі, так і спецыфічнымі для пэўнай платформы або інструмента[9].
Амальгамацыяй называецца спосаб экспарту мадэлі праз аб’яднанне ў адзін пакет параметраў мадэлі і ўсяго неабходнага коду для яе запуску. Такі пакет потым можа быць скампіляваны на патрэбнай платформе як асобная праграма. Гэты спосаб найбольш прыдатны для невялікіх і простых мадэлей, такіх як лагістычная рэгрэсія або дрэва рашэнняў. Напрыклад, для scikit-learn мадэлей такі пакет можна згенерыраваць з дапамогай бібліятэкі SKompiler. Пасля гэтага ён можа быць трансліраваны ў код на такіх мовах праграмавання як C, Javascript, Rust, Julia і г.д.[9]
Універсальныя фарматы
- PMML — фармат на аснове XML, файлы захоўваюцца з пашырэннем .pmml. Падтрымлівае толькі частку алгарытмаў машыннага навучання[9].
- PFA (Portable Format for Analytics) — мадэль захоўваецца ў JSON фармаце. Распрацоўваўся як замена PMML[9].
- ONNX (Open Neural Network eXchange) — фармат, які дазваляе запускаць мадэль незалежна ад фрэймворка распрацоўкі. Серыялізаваная з дапамогай ONNX мадэль можа рабіць прадказанні ў асяроддзях з адмысловымі бібліятэкамі. Сумяшчальны з большасцю інструментаў для глыбокага навучання. Падтрыманы шэрагам вялікіх кампаній, такіх як Microsoft, Facebook і Amazon[9].
Разгортванне мадэлі
Разгортванне сістэмы машыннага навучання складаецца з разгортвання пайплайна для навучання мадэлі і забеспячэння API, праз які мадэллю можна карыстацца для атрымання прадказанняў для новых даных. Працэс ператварэння запыта да мадэлі ў прадказанне завецца вывядзеннем. Вывядзенне патрабуе наяўнасці мадэлі, інтэрпрэтатара для выканання кода і ўваходных даных[9].
Часта мадэлі машыннага навучання разгортваюцца ў кантэйнерах, напрыклад з дапамогай Docker. Аркестроўка кантэйнераў ажыццяўляецца такімі інструментамі, як Kubernetes, AWS Fargate і іх альтэрнатывамі. Правайдэры воблачных сэрвісаў часта маюць уласныя платформы машыннага навучання з магчымасцю разгортвання мадэлей, напрыклад Amazon SageMaker, Google Cloud AI Platform, Azure Machine Learning Studio і IBM Watson Machine Learning. Альтэрнатыўна, мадэлі могуць быць разгорнуты як бессерверныя функцыі ў Azure Functions, AWS Lambda, Google Cloud Functions і інш. У такім выпадку код для выкарыстання мадэлі можа быць упакаваны ў .zip архіў, што перадаецца ў адпаведны сэрвіс[9].
Шаблоны разгортвання
Model-as-Service
Мадэль можа быць разгорнута як сэрвіс (англ.: Model-as-Service). У такім выпадку мадэль і інтэрпрэтатар аб’ядноўваюцца ў адзіны вэб-сэрвіс, карыстацца якім можна паводле REST API або gRPC[9].
Model-as-Dependency
У шаблоне Model-as-Dependency мадэль разглядаецца як залежнасць прыкладной праграмы, якая яе выкарыстоўвае. Напрыклад гэта можа быць стандартная jar-залежнасць, якая мае асобны метад для вывядзення, даступны праграме[9].
Precompute
У некаторых выпадках прадказанні мадэлі для ўваходных даных магчыма падлічыць яшчэ да атрымання гэтых даных, напрыклад калі набор усіх магчымых запытаў адносна невялікі. Тады навучаная мадэль выкарыстоўваецца для такога падліку толькі адзін раз і яе адказы запісваюцца ў базу даных. Пасля гэтага кожны запыт да мадэлі перанакіроўваецца ў базу даных для атрымання адпаведных прадказанняў[9].
Model-on-Demand
Для мадэлі ў шаблоне Model-on-Demand характэрны ўласны цыкл выпуску, незалежны ад іншых сэрвісаў. Мадэль і яе асяроддзе выканання аб’ядноўваюцца ў асобны кампанент пад назвай апрацоўшчык падзей. Узаемадзеянне з апрацоўшчыкам адбываецца праз брокер паведамленняў, які мае дзве чаргі: уваходную і выхадную. Сэрвіс, якому неабходныя прадказанні ад мадэлі, запісвае запыты ў уваходную чаргу. Апрацоўшчык падзей забірае запыты з уваходнай чаргі групамі, прымяняе да іх мадэль і запісвае вынікі ў выхадную чаргу. З выхадной чаргі прадказанні перадаюцца назад у той сэрвіс, што пасылаў запыты[9].
Hybrid-Serving (федэратыўнае навучанне)

Шаблон Hybrid-Serving, вядомы таксама як федэратыўнае навучанне, прадугледжвае наяўнасць уласнай мадэлі для кожнага карыстальніка, якая захоўваецца лакальна на карыстальніцкай прыладзе, напрыклад на смартфоне. Акрамя лакальных мадэлей існуе навучаная на гістарычных даных глабальная мадэль на серверы, паводле якой ствараюцца лакальныя мадэлі. Лакальныя мадэлі дадаткова навучаюцца на карыстальніцкіх даных без адпраўкі гэтых даных на сервер. Перыядычна параметры лакальных мадэлей адпраўляюцца назад на сервер, глабальная мадэль камбінуе іх і абнаўляецца, а вынікі камбінавання перадаюцца лакальным мадэлям для іх удасканалення. Тэсціраванне мадэлі адбываецца лакальна на прыладах, дзе захоўваюцца даныя карыстальнікаў[9].
Перавагі такога метаду ў тым, што ён не патрабуе адпраўкі карыстальніцкіх даных, магчыма канфідэнцыяльных, на сервер, але ўсё адно дазваляе выкарыстоўваць іх для навучання мадэлі. Пры гэтым накладаюцца абмежаванні як на тэхнічныя характарыстыкі лакальных прылад, так і на памер і іншыя тэхнічныя патрабаванні самой мадэлі, таму федэратыўнае навучанне не заўсёды магчыма на практыцы[9].
Зноскі
- ↑ ML Ops: Machine Learning as an Engineering Discipline (англ.). Towards Data Science. Праверана 6 July 2021.
- 1 2 3 MLOps: Motivation (англ.). ML Ops: Machine Learning Operations. Праверана 15 лістапада 2023.
- ↑ MLOps Market Size, Share and Global Market Forecast to 2027 (англ.). MarketsandMarkets. Праверана 15 лістапада 2023.
- 1 2 3 4 5 6 7 8 9 10 11 12 MLOps Principles (англ.). ML Ops: Machine Learning Operations. Праверана 25 лістапада 2023.
- ↑ MLOps Roadmap 2022 (англ.). Праверана 25 снежня 2023.
- 1 2 MLOps: Phase Zero (англ.). ML Ops: Machine Learning Operations. Праверана 20 лістапада 2023.
- 1 2 3 Ajay Agrawal, Joshua Gans, Avi Goldfarb. A Simple Tool to Start Making Decisions with the Help of AI (англ.). Harvard Business Review (17 красавіка 2018). Праверана 20 лістапада 2023.
- 1 2 3 End-to-end Machine Learning Workflow (англ.). ML Ops: Machine Learning Operations. Праверана 4 снежня 2023.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Three Levels of ML Software (англ.). ML Ops: Machine Learning Operations. Праверана 13 снежня 2023.