مسح هيكلة الشجرة
في علم الحاسوب، يُمثل مسح (اجتياز) الشجرة (المعروف أيضًا باسم البحث في الشجرة وبالإنجليزية tree traversal) شكلًا من أشكال مسح الرسم البياني ويشير إلى عملية زيارة (فحص و / أو تحديث) كل عقدة في هيكلة الشجرة للبايانات، مرة واحدة بالضبط. تختلف أنواع المسح حسب ترتيب زيارة رؤوس الشجرة. الخوارزميات التالية خاصة ببنية الشجرة الثنائية، ولكن قد تُعمم على هياكل الأشجار الأخرى أيضًا.
أنواع المسح
على عكس القوائم المتسلسلة، والمصفوفات أحادية البعد وغيرها من هياكل البيانات الخطية، والتي تُمسح (تجتاز) ببساطة وبترتيب خطي، قد تُمسح الأشجار بطرق متعددة. فقد تمسح بترتيب «العرض أولا» أو «العمق أولا». هناك ثلاث طرق شائعة لعبورها بترتيب العمق أولا وهي كالتالي: ترتيب، ترتيب مسبق، ترتيب لاحق.[1] إلى جانب طرق العبور الأساسية هذه، توجد مخططات أكثر تعقيدًا أو هجينة، مثل عمليات البحث محدودة العمق أو مثل البحث التكراري بالعمق المتعمق الأول.
هياكل البيانات لمسح الشجرة
مسح شجرة ينطوي على تتابع العبور على جميع الرؤوس بطريقة ما. نظرًا لوجود أكثر من رأس ابن واحد محتمل من رأس ما (ليست بنية بيانات خطية)، إذن، بافتراض حوسبة متسلسلة (وليس موازية)، يجب تأجيل بعض الرؤوس - تُخزن بطريقة ما للزيارة لاحقا. تخزن غالبًا عبر مكدس (LIFO) أو طابور (FIFO). نظرًا لأن الشجرة عبارة عن بنية بيانات ذات مرجعية ذاتية (محددة عوديا)، يمكن إجراء المسح عوديا أو، بشكل أكثر دقة، مزدوج العودية، بطريقة سهلة وواضحة للغاية؛ في هذه الحالات، تخزن ضمنيًا الرؤوس المؤجلة في مكدس الاستدعاءات.
يمكن تطبيق بحث «العمق أولا» بسهولة عبر بنية المكدس، بما في ذلك عوديا (عبر مكدس الاستدعاءات)، في حين يُنفذ بحث «العرض أولا» بسهولة عبر بنية الطابور، بما في ذلك بشكل متزامن.
بحث العمق أولا
يشار إلى هذا البحث ببحث العمق أولا (DFS)، حيث يُمسح كل ابن لشجرة البحث قدر الإمكان (تعميق المسح) قبل الانتقال إلى الأخ التالي. بالنسبة للشجرة الثنائية، يكون البحث عن طريق العرض العَوْدِي على كل رأس، بدءًا من الجذر، وتكون خوارزميتها كالتالي:
النمط العودية العام لعبور (اجتياز) شجرة ثنائية (غير فارغة) هو:
عند الرأس N قم بالآتي:
(L) امسح عَوْدِيًا شجيرتها الفرعية اليسرى. تنتهي هذه الخطوة في الرأس N مرة أخرى.
(R) امسح عَوْدِيًا شجيرتها الفرعية اليمنى. تنتهي هذه الخطوة في الرأس N مرة أخرى.
(N)تقوم بالعملية على نفسها.
يمكن القيام بهذه الخطوات بأي ترتيب. إذا نُفذت (L) قبل (R)، فستسمى العملية مسح من اليسار إلى اليمين، وإن كان العكس تسمى مسح من اليمين إلى اليسار. تُظهر الطرق التالية عملية مسح من اليسار إلى اليمين:
ترتيب السابق (NLR)

- تحقق مما إذ كان الرأس الحالي فارغًا أو خاليًا.
- عرض بيانات الجذر (أو الرأس الحالي).
- مسح الشجرة الفرعية اليسرى عن طريق استدعاء عَوْدِي لدالة الترتيب المسبق.
- مسح الشجرة الفرعية اليمنى عن طريق استدعاء عَوْدِي لدالة الترتيب المسبق.
مسح الترتيب المسبق هو مسح مرتب طوبولوجيا، حيث يمسح الرأس الأب قبل أبنائه.
في الترتيب (LNR)

- تحقق مما إذ كانت الرأس الحالي فارغًا أو خاليًا.
- مسح الشجرة الفرعية اليسرى عن طريق استدعاء عَوْدِي لدالة في الترتيب.
- عرض بيانات الجذر (أو الرأس الحالي).
- امسح الشجرة الفرعية اليمنى عن طريق استدعاء عَوْدِي لدالة في الترتيب.
في شجرة البحث الثنائية، يُظهر مسح في الترتيب بيانات الشجرة بطريقة مرتبة تصاعديا.[4]
خارج الترتيب (RNL)
- تحقق مما إذ كانت الرأس الحالي فارغًا أو خاليًا.
- امسح الشجرة الفرعية اليمنى عن طريق استدعاء عَوْدِي لدالة خارج الترتيب.
- عرض بيانات الجذر (أو الرأس الحالي).
- مسح الشجرة الفرعية اليسرى عن طريق استدعاء عَوْدِي لدالة خارج الترتيب.
في شجرة البحث الثنائية، يُظهر مسح في الترتيب بيانات الشجرة بطريقة مرتبة تنازليا.
الترتيب اللاحق (LRN)

- تحقق مما إذ كانت الرأس الحالي فارغًا أو خاليًا.
- مسح الشجرة الفرعية اليسرى عن طريق استدعاء عَوْدِي لدالة بعد الترتيب.
- امسح الشجرة الفرعية اليمنى عن طريق استدعاء عَوْدِي لدالة بعد الترتيب.
- عرض بيانات الجذر (أو الرأس الحالي).
مسار مسح بنية الشجرة عبارة عن سَلْسَلَة للشجرة. وهو قائمة متسلسلة للرؤوس المجتازة. ليس هناك سَلْسَلَة قائمة على الترتيب السابق أو اللاحق تصف الشجرة الأصلية وصفا دقيقًا وفريدًا. في حالة شجرة ذات عناصر مختلفة، فيمكن استعمال إما الترتيب اللاحق أو السابق مقرونين بدالة في الترتيب، للحصول على سَلْسَلَة تصف الشجرة الأصلية بدقة وبشكل فريد. ومع ذلك، فإن الترتيب السابق واللاحق يتركان بعض الغموض في بنية الشجرة.[5]
بنية شجرة من أي نوع
لمسح أي شجرة من خلال بحث «العمق أولا»، نفذ العمليات التالية عَوْديًا على كل رأس شجرة:
- نفذ عملية الترتيب السابق.
- لكل ط من 1 إلى عدد الأبناء قم بما يلي:
- زيارة الرأس ط، إذا كان موجودا.
- نفذ عملية في الترتيب.
- نفذ عملية الترتيب اللاحق.
اعتمادًا على المشكلة المطروحة، قد لا تستعمل واحدة من العمليات السابقة، أو قد ترغب في زياة ابن محدد، لذلك قد تكون هذه العمليات اختيارية. أيضًا، في الممارسة العملية، قد تكون هناك حاجة إلى أكثر من واحدة من العمليات السابقة، على سبيل المثال، عند الإدراج في شجرة ثلاثية، يتم تنفيذ عملية ترتيب سابق بمقارنة العناصر. قد تكون هناك حاجة لعملية الترتيب اللاحف لإعادة التوازن إلى الشجرة.
بحث «العرض أولا»

يمكن أيضًا مسح بنى الأشجار بترتيب مستوى، حيث نزور كل رأس في المستوى الحالي قبل الانتقال إلى المستوى الأدنى. يشار إلى هذا البحث باسم بحث «العرض أولا»، حيث مسح شجرة البحث بالعرض قدر عرضها في كل عمق قبل الانتقال إلى العمق التالي.
أنواع أخرى
هناك أيضًا خوارزميات مسح بنية الأشجار التي تُصنف على أنها لا بحث «العمق أولا» ولا بحث «العرض أولا». إحدى هذه الخوارزميات هي شجرة بحث مونت كارلو، والذي يركز على تحليل التحركات المتوقعة، معتمدا على تمديد شجرة البحث بأخذ عينات عشوائية من مساحة البحث.
تطبيقات المسح
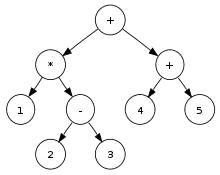
يمكن مضاعفة شجرة ثنائية عن طريق مسح ذو ترتيب سابق بمضاعفة الرؤوس والأطراف (الأوراق)، وتُستعمل أيضا لعمل عبارة بادئة (التدوين البولندي) من شجرة التحليل ومسحها بترتيب سابق. على سبيل المثال مسح بترتيب سابق للشجرة الموضحة في الشكل أعلاه يُنتج "5 4 + 3 2 - 1 * +".
يشيع استخدام مسح في الترتيب على أشجار البحث الثنائية لأنه يُرجع قِيّم الشجرة الأصلية مرتبة، حسب المقارن الذي على أساسه بنيت شجرة البحث الثنائية (وفقا لاسمها).
يمكن تحرير أو حذف شجرة ثنائية بأكملها عن طريق المسح بالترتيب اللاحق وذلك بحذف وتحرير الرؤوس وقيمها. يمكنه أيضا إنتاج تمثيل لاحق لشجرة ثنائية، مسح بترتيب لاحق للشجرة الموضحة في الشكل أعلاه يُنتج "+ 5 4 * - 3 2 1".
تطبيق عملي
ترتيب سابق
ترتيب_سابق_بالتكرار(رأس) إذا (رأس = خالٍِ) أرجع م → مكدس فارغ م.دفع (رأس) طالما (نفي م.فارغة ()) رأس → م.طرح () زيارة (رأس) //الابن الأيمن يُدفع أولا كي يُعالج الابن الأيسر أولا إذا (رأس.يمين ≠ خالٍ) م.دفع (رأس.يمين) إذا (رأس.يسار≠خالٍ) م.دفع (رأس.يسار) |
ترتيب_سابق(رأس) إذا (رأس = خالٍ) أرجع زيارة (رأس) ترتيب_سابق (رأس.يسار) ترتيب_سابق (رأس.يمين) |
بالترتيب
بالترتيب (رأس) إذا (رأس = خالٍ) أرجع بالترتيب (رأس.يسار) زيارة (رأس) بالترتيب (رأس.يمين) |
بالترتيب_تكرارية (رأس) م → مكدس فارغ طالما (نفي م.فارغة () أو رأس ≠خالٍ) إذا (رأس ≠خالٍ) م.إدفع (رأس) رأس → رأس.يسار وإلا رأس → م.طرح () زيارة (رأس) رأس →رأس.يمين |
ترتيب لاحق
ترتيب_لاحق (رأس) إذا (رأس = خالٍ) أرجع ترتيب_لاحق (رأس.يسار) ترتيب_لاحق (رأس.يمين) زيارة (رأس) |
iterativePostorder (عقدة) ق ← كومة فارغة lastNodeVisited ← فارغة بينما (وليس s.isEmpty () أو العقدة فارغة) إذا (العقدة فارغة) s.push (عقدة) العقدة ← العقدة آخر peekNode ← s.peek () / / إذا كان الطفل المناسب موجودًا ويتجاوز العقدة // من الطفل الأيسر، ثم تحرك يمينًا إذا (peekNode.right ≠ null و lastNodeVisited ≠ peekNode.right) العقدة ← peekNode.right آخر زيارة (peekNode) lastNodeVisited ← s.pop () |
تتطلب الإجراءات السابقة مكدس به مساحة كافية لطول الشجرة والذي يسمى بمكدس الإستدعاء في حالة الإجراء العودي وبالمكدس الأب في حالة الحلقات التكرارية.
في شجرة متوازنة، يجب الأخذ بعين الاعتبار عند استعمال الإجراءات التكرارية أنه يمكننا إزالة متطلبات المكدس من خلال الحفاظ على المؤشرات الرئيسية في كل رأس، أو عن طريق نظم الشجرة (القسم الآتي).
مسح بالترتيب لموريس باستعمال التشعب (شريط التعليمات)
يُنفذ الخيط على شجرة ثنائية عن طريق جعل كل مؤشر كل ابن على اليسار (يمكن أن يكون خاليًا)، يشير إلى دالة بالترتيب السالفة للرأس (إن وُجدت). وكل مؤشر ابن على اليمين (يمكن أن يكون خاليًا)، يشير إلة دالة الترتيب اللاحقة للرأس (إن وُجدت).
مزايا:
- يتجنب العودية واستخدامها لمكدس الإستدعاء واستهلاكها للذاكرة والوقت.
- يحتفظ الرأس بسجل عن الرأس الأب.
سلبيات:
- الشجرة معقدة أكثر.
- نستطيع المسح مرة واحدة في وقت واحد.
- معرض للأخطاء الأخطاء عندما لا يكون كل من الأبناء موجودين وتشير كل من قيم الرأس إلى أبائهم.
مسح موريس هو تحقيق لمسح بالترتيب يستخدم الخيوط: [6]
- إنشاء روابط لسابقة دالة بالترتيب.
- اطبع البيانات باستخدام هذه الروابط.
- التراجع عن التغييرات لاستعادة الشجرة الأصلية.
بحث العرض أولًا
تماما كما سبق التالي عبارة عن شبه شفرة لمسح بسيط حسب ترتيب المستويات وعن طريق طابور. والذي سيحتاج إلى مساحة كافية لأكبر عدد ممكن من الرؤوس عند عمق معين. حيث تساوي هذه المساحة نصف عدد الرؤوس. يمكن تطبيق نهج أكثر كفاءة في استخدام المساحة لهذا النوع من التطبيق باستخدام بحث تعميق العمق أولا بالتكرار.
المستوى (الجذر) q ← طابور فارغ q.enqueue (الجذر) بينما (وليس q.isEmpty ()) العقدة ← q.dequeue () زيارة (عقدة) إذا (node.left ≠ خالية) q.enqueue (node.left) إذا (node.right ull null) q.enqueue (node.right)
أشجار لانهائية
عادة ما يكون المسح على الأشجار محدودة عدد الرؤوس (وبالتالي العمق وعامل التّفرع محدودان) لكن يمكن تطبيقه أيضا على أشجار غير محدودة (لانهائية). هذا أمر ذو أهمية خاصة في البرمجة الوظائفية (خاصةً مع التثمين الكسول)، حيث يمكن في كثير من الأحيان إعلان هياكل البيانات اللانهائية بسهولة والعمل معها، على الرغم من عدم تقييمها (بشكل صارم)، لأن هذا سيستغرق وقتًا غير محدود. بعض الأشجار المحدودة أكبر من أن تمثلها بشكل صريح، مثل شجرة اللعبة للشطرنج أو غو، ولذا فمن المفيد تحليلها كما لو كانت غير محدودة.
الشرط الأساسي للمسح هو زيارة كل رأس في نهاية المطاف. بالنسبة إلى الأشجار اللانهائية، غالبًا ما تفشل الخوارزميات البسيطة في ذلك. على سبيل المثال، في حالة وجود شجرة ثنائية ذات عمق غير محدود، فإن بحث العمق أولاً سيذهب في جانب واحد (عن طريق الجانب الأيسر) من الشجرة، ولن يزور الباقي أبدًا، ومن المؤكد أن المسح بالترتيب اللاحق أو الترتيب السابق لن يزور أية رأس، لأنها لم تصل إلى ورقة (وفي الواقع لن تفعل ذلك أبدا). على النقيض من ذلك، فإن مسح العرض أولا (ترتيب المستوى) سيعبر شجرة ثنائية ذات عمق لا متناهٍ دون مشكلة، وفي الواقع سيمسح أي شجرة بعامل تفرع محدد.
من ناحية أخرى، وبالنظر إلى شجرة بعمق يساوي 2، حيث يحتوي الجذر على عدد لا حصر له من الأبناء، ولكل من هؤلاء الأبناء إبنان، سيزور بحث العمق أولا جميع الرؤوس، بمجرد اكمال الأحفاد (أبناء أبناء رأس معين)، سيتم الانتقال إلى التالي (على افتراض أنه ليس ترتيبًا لاحقًا، وفي هذه الحالة لا يصل إلى الجذر مطلقًا). على النقيض من ذلك، لن يصل بحث العرض أولا إلى الأحفاد، لأنه يسعى إلى اكمال الأبناء أولاً.
يمكن تقديم تحليل أكثر تطوراً لوقت التشغيل عبر الأرقام الترتيبية اللانهائية؛ على سبيل المثال، سيتخذ بحث العرض لشجرة العمق 2 أعلاه خطوات ω · 2: ω للمستوى الأول، ثم ω للمستوى الثاني.
وبالتالي، فإن عمليات البحث البسيطة الأولى أو العميقة الأولى لا تجتاز كل شجرة لا نهائية، وليست فعالة في الأشجار الكبيرة جدًا. ومع ذلك، يمكن للطرق الهجينة اجتياز أي شجرة لا حصر لها (قابلة للعد)، وذلك بشكل أساسي عبر وسيطة قطرية («قطري» - مزيج من الرأسي والأفقي - يتوافق مع مزيج من العمق والاتساع).
بشكل ملموس، بالنظر إلى شجرة المتفرعة بلا حدود من العمق اللانهائي، قم بتسمية الجذر ()، أبناء الجذر (1)، (2)... أحفاد (1، 1)، (1، 2)... (2)، 1)، (2، 2)... وهلم جرا. العقد هي بالتالي في واحد إلى واحد مراسلات مع تسلسل محدود (ربما فارغة) من أرقام موجبة، والتي هي قابل للعد ويمكن وضعها في الدرجة الأولى من مجموع الإدخالات، ومن ثم من قبل النظام lexicographic ضمن مبلغ معين (إلا بشكل محدود تُلخص العديد من التسلسلات بقيمة معينة، وبالتالي يتم الوصول إلى جميع المدخلات - هناك عددًا محدودًا من التراكيب ذات العدد الطبيعي المحدد، وتحديداً التراكيب 2 n − 1 من n ≥ 1)، والتي تعطي اجتيازًا. صراحة:
0: () 1: (1) 2: (1، 1) (2) 3: (1، 1، 1) (1، 2) (2، 1) (3) 4: (1، 1، 1، 1) (1، 1، 2) (1، 2، 1) (1، 3) (2، 1، 1) (2، 2) (3، 1) (4)
إلخ
يمكن تفسير ذلك على أنه تعيين الشجرة الثنائية العمق اللانهائية على هذه الشجرة ثم تطبيق بحث اتساع: استبدل الحواف «السفلية» التي تربط العقدة الرئيسية بأطفالها الثانيين واللاحقين بأطراف «يمينية» من الطفل الأول إلى الثاني الطفل، من الطفل الثاني إلى الطفل الثالث، إلخ. وبالتالي في كل خطوة، يمكن للمرء إما النزول (إلحاق (، 1) إلى النهاية) أو الانتقال يمينًا (إضافة واحد إلى الرقم الأخير) (باستثناء الجذر، وهو إضافي ويمكنه فقط)، مما يدل على المراسلات بين الشجرة الثنائية اللانهائية والترقيم أعلاه؛ مجموع المدخلات (ناقص واحد) يتوافق مع المسافة من الجذر، والتي تتفق مع العقد 2 n −1 على عمق n − 1 في الشجرة الثنائية اللانهائية (2 يتوافق مع الثنائية).
المراجع
- "Lecture 8, Tree Traversal". مؤرشف من الأصل في 2018-08-05. اطلع عليه بتاريخ 2015-05-02.
- (PDF) https://web.archive.org/web/20170828233302/https://www.cise.ufl.edu/~sahni/cop3530/slides/lec216.pdf. مؤرشف من الأصل (PDF) في 2017-08-28.
{{استشهاد ويب}}: الوسيط|title=غير موجود أو فارغ (مساعدة) - "Preorder Traversal Algorithm". مؤرشف من الأصل في 2019-04-11. اطلع عليه بتاريخ 2015-05-02.
- Wittman، Todd. "Tree Traversal" (PDF). جامعة كاليفورنيا (لوس أنجلوس) Math. مؤرشف من الأصل (PDF) في 2015-02-13. اطلع عليه بتاريخ 2016-01-02.
- "Algorithms, Which combinations of pre-, post- and in-order sequentialisation are unique?, Computer Science Stack Exchange". مؤرشف من الأصل في 2019-04-11. اطلع عليه بتاريخ 2015-05-02.
- Morris، Joseph M. (1979). "Traversing binary trees simply and cheaply". Information Processing Letters. ج. 9 ع. 5. DOI:10.1016/0020-0190(79)90068-1.
- عامة
- ديل، نيل. ليلي، سوزان د. «هياكل بيانات باسكال بلس». العاصمة هيث وشركاه. ليكسينغتون، ماساتشوستس. عام 1995. طبعة رابعة.
- دروزديك، آدم. «هياكل البيانات والخوارزميات في C ++». بروك / كول. باسيفيك جروف، كاليفورنيا عام 2001. الطبعة الثانية.
- http://www.math.northwestern.edu/~mlerma/courses/cs310-05s/notes/dm-treetran
روابط خارجية
- تخزين البيانات الهرمية في قاعدة بيانات مع أمثلة اجتياز في PHP
- إدارة البيانات الهرمية في MySQL
- العمل مع الرسوم البيانية في الخلية
- رمز عينة لاجتياز شجرة تكرارية وتكرارية مطبق في C.
- رمز عينة لاجتياز شجرة العودية في C #.
- انظر اجتياز شجرة تنفيذها في لغة البرمجة المختلفة على رمز رشيد
- اجتياز شجرة دون العودية
 بوابة علم الحاسوب
بوابة علم الحاسوب