تنقيب الويب
التنقيب على الويب هو تطبيق لتقنيات التنقيب عن البيانات لاكتشاف الأنماط من شبكة الويب العالمية. يستخدم طرقًا آلية لاستخراج البيانات المهيكلة وغير المهيكلة من صفحات الويب وسجلات الخادم وهياكل الارتباط. هناك ثلاث فئات فرعية رئيسية لتعدين الويب. استخراج محتوى الويب يستخرج المعلومات من داخل الصفحة. يكتشف التعدين في بنية الويب بنية الارتباطات التشعبية بين المستندات، ويصنف مجموعات من صفحات الويب ويقيس التشابه والعلاقة بين المواقع المختلفة. يكتشف التنقيب عن استخدام الويب أنماط استخدام صفحات الويب.
أنواع التنقيب عن الويب
يمكن تقسيم تعدين الويب إلى ثلاثة أنواع مختلفة - التنقيب عن استخدام الويب وتعدين محتوى الويب وتعدين بنية الويب.
1. المقدمة والمعلومات الاساسية
في عالم الحاسوب، البيانات تمثل مجالا مثيرا للاهتمام. انها في ازدياد مستمر وتتوسع بشكل كبير، وإنه من المهم بالنسبة لنا العثور على معلومات مفيدة من هذه البيانات الضخمة. العملية الشاملة لتحليل مجاميع البيانات، للعثور على معلومات مفهومة ومفيدة لأصحاب البيانات، تسمى تنقيب البيانات.[1] في السنوات القليلة الماضية، تم تخزين معظم البيانات التي تملكها المؤسسات في مخازن مهيكلة للبيانات مثل قواعد البيانات العلائقية. هذه البيانات يمكن الوصول إليها بسهولة لأغراض التنقيب باستخدام العديد من تقنيات استخراج البيانات.[1] مع ذلك، فقد تغيرت طبيعة البيانات بشكل كبير منذ ظهور شبكة الإنترنت، والتي لديها مميزات وخصائص تجعلها مختلفة عن البيانات المهيكلة. هذه الخصائص يمكن تلخيصها على النحو التالي:[2]
1. الحجم الضخم للبيانات على الويب وما زالت تنمو اضعافا مضاعفة.
2. الويب يحتوي على بيانات من مختلف الانواع والاشكال. ذلك يشمل البيانات المهيكلة مثل الجدول، والبيانات شبه المهيكلة مثل وثائق الإكس أم أل (XML)، وبيانات غير مهيكلة مثل النصوص في صفحات الويب، وبيانات متعددة الوسائط مثل الصور والافلام.
3. عدم تجانس المعلومات على شبكة الإنترنت. مؤلفون من حول العالم يشاركون في بناء محتوى الويب. نتيجة لذلك. قد تجد صفحات ذات محتوى شبيه أو متطابق.
4. بيانات الويب تمتلك وصلات تشعبية، وهو ما يعني أن صفحات الويب ترتبط معا بحيث يمكن لأي شخص التنقل من خلال صفحات داخل الموقع نفسه أو عبر مواقع مختلفة. هذه الوصلات يمكن أن تخبرنا كيف يتم تنظيم المعلومات بين الصفحات داخل الموقع، ومدى قوة أو ضعف العلاقة ما بين الصفحات عبر مواقع مختلفة.
5. ضجيج المعلومات على الويب. أسباب ذلك هما قضيتان. أولا، صفحة الويب النموذجية عادة ما تحتوي على العديد من المعلومات مثل الجسم الرئيسي للصفحة، وصلات، والإعلانات، وغيرها الكثير. وبالتالي، فإن الصفحة لا توجد لديها بنية محددة. ثانيا، ليست هناك سيطرة نوعية على المعلومات، بمعنى أنه يمكن لأي شخص تحميل محتوى على الويب بغض النظر عن نوعيته أو جودته.
6. جزء كبير من المحتوى على شبكة الإنترنت يُعتبر ديناميكي، وهذا يعني أنه يتم تحديث المعلومات في كثير من الأحيان وبشكل مستمر. على سبيل المثال، معلومات الطقس يتم تحديثها بشكل مستمر.
7. الويب يحتوي على مواقع التجارة الإلكترونية التي تمكن الناس من أداء العديد من عمليات الشراء، وتحويل الأموال، وغيرها الكثير. هذا النوع من المواقع يحتاج إلى تزويد العملاء بخدمات محوسبة مثل نظام التوصية.
8. الويب ليس مجرد بيانات ومعلومات. في الوقت الحاضر، يعتبر ويب مجتمع افتراضي، حيث يمكن للناس والمنظمات وحتى الانظمة المحوسبة التواصل والتفاعل مع بعضها البعض. كل هذه الخصائص تجعل عملية استخراج البيانات على الشبكة أكثر تحديا، وفي نفس الوقت تعطينا فرصا لاكتشاف المعرفة المفيدة والقيّمة من الويب. ونظرا لوجود مجموعة واسعة من أنواع البيانات أصبحت تقنيات استخراج البيانات التقليدية غير كافية.[2] وهذا ما أدى إلى تبلور حاجة لتطوير تقنيات وخوارزميات جديدة تهدف تنقيب البيانات على شبكة الإنترنت. العديد من الباحثين مثل عتيق وآخرون[3] وتشانغ وسيغال[4] يعتقدون أن استخراج البيانات التقليدية تتعامل بشكل رئيسي مع البيانات المهيكلة التي يتم تخزينها في قواعد البيانات العلائقية، في حين تنقيب ويب تتعامل مع بيانات الويب، التي عادة ما تكون شبه مهيكلة أو غير مهيكلة. آخرون مثل إتزيوني[5]، وماركوف وآخرون[6]، وكوسالا وبلوكيل[7] يرون تنقيب الويب كتطبيق على منهجيات وتقنيات ونماذج استخراج البيانات. ليو[2] يشير إلى أن العديد من تقنيات استخراج البيانات التقليدية يمكن تطبيقها في العديد من مهام تنقيب الويب. ومع ذلك، فهو يرى أن تنقيب الويب ليس تماما تطبيق لاستخراج البيانات التقليدية نظرا للخصائص التي يمتاز بها الويب والتي تم نقاشها أعلاه. هناك تعريف جيد لمصطلح تنقيب الويب والتي قدمها ليو:[2] يهدف تنقيب الويب إلى إيجاد واستخراج المعلومات المفيدة من بيانات الويب، والتي تشمل: هياكل الارتباطات التشعبية، محتوى صفحات الويب، وسجلات استخدام الويب. الغالبية العظمى من الباحثين مثل ليو[2]، ومادريا وآخرون[8]، وبورخيس ويفين[9] يتفقون على أن تنقيب الويب يمكن تقسيمها إلى ثلاث فئات بناءً على الجزء المنوي تنقيبه؛ وهم: تنقيب هيكلية الويب، والتي تسعى إلى كشف معلومات مفيدة من بنية الارتباط التشعبي للشبكة، وتنقيب محتوى ويب، والتي تهدف إلى استخراج المعلومات المفيدة من محتوى صفحات الويب، وأخيرا تنقيب استخدام الويب، والتي تنطوي على إيجاد أنماط وصول المستخدم. سأقوم بمناقشة كل واحد منهما على حدة في الاقسام اللاحقة. عملية تنقيب الويب مشابهة إلى حد ما عملية استخراج البيانات التقليدية، والتي تتكون أساسا من ثلاث خطوات رئيسية: مرحلة ما قبل المعالجة، لتحويل البيانات الخام إلى شكل يمكن أن يكون مناسبة للتنقيب، واستخراج البيانات، والتي يتم فيها تطبيق خوارزمية تحليل البيانات وتجهيزها، ومرحلة ما بعد المعالجة، للتّعرف على بيانات مفيدة باستخدام التقييم وتقنيات التصور.[10] مع ذلك، جمع البيانات مختلف تماما عن ما هو في استخراج البيانات التقليدية. في استخراج البيانات التقليدية، تستخدم مستودعات البيانات لجمع وتخزين البيانات، في حين أنه في تنقيب الويب، جمع البيانات هي مهمة صعبة وتتطلب سحب عدد كبير من صفحات الويب.[2] علاوة على ذلك، التقنيات المستخدمة في كل خطوة مختلفة تماما في تنقيب الويب.[2] آخرون مثل إتزيوني[5]، وكوسالا وبلوكيل[7]، وتشانغ وسيغال[4] يقسمون عملية تنقيب الويب إلى المراحل التالية:
1. جمع الموارد: لاسترجاع وجمع مستندات ويب.
2. اختيار المعلومات ومرحلة ما قبل المعالجة: لتحديد بيانات محددة وتحويلها إلى شكل ملائم للمعالجة.
3. التعميم: لاكتشاف الأنماط والتعرف عليها.
4. التحليل: للتحقق من صحة المعلومات التي تم استخراجها والعمل على تمثيلها بطريقة مناسبة. تتمحور بقية هذه المقالة البحثية على النحو التالي: في القسمين الثاني والثالث، والرابع، سأعرض فئات تنقيب الويب، وهي: تنقيب هيكلية الويب وتنقيب محتوى ويب، وتنقيب استخدام الويب على التوالي. ثم سألخص هذه المقالة مع الإشارة إلى بعض الاتجاهات المستقبلية في القسم الخامس والاخير.
2. تنقيب هيكلية الويب
نعني بتنقيب هيكلية الويب استخدام بنية الارتباط التشعبي على الشبكة كمصدر للمعلومات في عملية التنقيب.[7] الارتباطات التشعبية تمثل واحدة من السمات الخاصة للشبكة وكذلك أساس الويب. ترتبط كل صفحات ويب ببعضها البعض عن طريق وصلات بحيث يمكن للمستخدم التنقل من صفحة إلى أخرى من خلالها.[2] تنقيب هيكلية الويب تهدف إلى استخراج معرفة مفيدة مجردة من بنية الارتباط التشعبي على الشبكة لأغراض عديدة.[2] بعض التقنيات المستخدمة في تنقيب هيكلية الويب مستوحاة من تحليل الشبكات الاجتماعية التي يمكن من خلالها أن نجد أنواع معينة من الصفحات مثل المحاور والسلطات والمجتمعات بناءً على الروابط الواردة والصادرة.[11] في الفقرات التالية، سأناقش بعض مهام تنقيب هيكلية الويب مع تقنياتهم بشكل مختصر.
أ. تحسين نتائج بحث الويب
استخراج المعرفة من بنية الارتباط التشعبي مهم جدا لمحركات البحث بحيث يمكن اكتشاف صفحات الويب ذات الصلة.[12] في محركات البحث البدائية على الإنترنت، كانت طرق استرجاع المعلومات وحدها غير كافية لترتيب النتائج التي يتم إرجاعها من قبل محركات البحث على الويب. مع وجود الارتباطات التشعبية، وجد الباحثون أن النتائج التي يتم استرجاعها يمكن تحسينها بشكل ملحوظ.[2]
تشير
الارتباطات تشعبية إلى صفحات داخل الموقع، وبالتالي تٌنظم تدفق المعلومات داخل
الموقع. كما أنها يمكن أن تشير إلى صفحات عبر مواقع مختلفة، بمعنى ان صفحة ويب
تشير إلى صفحة في موقع ويب آخر. يمكن لهذه الارتباطات التشعبية ان تشير إلى وجود
نوع من التأييد الضمني للصفحات المُشار اليها.[12] وبعبارة أخرى، فإن بنية
الارتباط التشعبي تمثل الهيكل الاجتماعي الأساسي الذي يدل على فهم أهمية ونوعية
صفحات الويب.[12] تم اقتراح اثنتين من الخوارزميات القائمة على الارتباط التشعبي
خلال الفترة ما بين 1997 و 1998، وهي: البيج رانك (PageRank)[13] والبحث الموضوعي
التشعبي أو هيتس (HITS).[14]

البيج رانك هي الخوارزمية التي جعلت جوجل محرك بحث ناجح من بين الآخرين. واحدة من مميزاته أنه لا يعتمد على الاستعلام عند تقييم صفحات ويب. خوارزمية البيج رانك تعتمد بشكل رئيسي على معلومتين: الروابط الداخلة لصفحة س، وهي الوصلات التي تشير إلى الصفحة س من صفحات أخرى، والروابط الخارجة من الصفحة س، وهي الوصلات التي تشير إلى صفحات أخرى من الصفحة س.[13] البيج رانك تعتمد على فكرة البريستيج المستخدمة في تحليل الشبكات الاجتماعية.[11] الفكرة الرئيسية للبيج رانك هي كما يلي:[13]
1. كلما كان هنالك روابط تشير إلى الصفحة س، كلما زاد الدعم، كلما زادت قيمة البريستيج.
2. كلما زاد عدد الصفحات ذات البريستيج العالي التي تشير إلى الصفحة س، كلما زادت أهمية الصفحة س.
البيج
رانك تحول بنية الارتباط التشعبي للويب إلى رسم بياني موجه.[13] في الصورة 1[2]، كل دائرة أو عقدة تمثل صفحة ويب. صفحة الويب 1 لها وصلتان
خارجتان (إلى العقد 2 و 3) وواحدة داخلة (من عقدة 2) على سبيل المثال. لمزيد من
التفاصيل حول حسابات البيج رانك، يمكن العثور عليها في.[13]
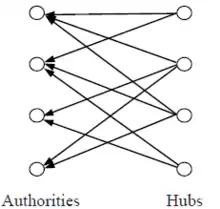
بينما البيج رانك لا يعتمد على الاستعلام، هيتس تعتمد على الاستعلام. عندما يقوم المستخدم بالاستعلام عن شيء ما، هيتس تحاول جمع مجموعة من صفحات الويب ذات الصلة التي تم إرجاعها بواسطة محرك البحث. ثم يقوم بإعطاء تقديرات عددية تسمى اوزان المحور والسلطة باستخدام نهج متكرر. يطلق على الصفحة سلطة إذا كان لديها العديد من الروابط الداخلة، بمعنى ان الصفحة تحتوي على محتوى موثوق به وكثير من الناس يؤيدون ذلك. يطلق على الصفحة محور إذا كان لديها العديد من الروابط الخارجة.[14] الصورة 2[2] توضح مثالا على مجموعة من السلطات والمحاور. لمزيد من التفاصيل حول حسابات هيتس، يمكن العثور عليها في.[12][14] يتم حساب البيج رانك، والسلطة، والمحور باستخدام طريقة تكرار القوة.[2]
ب. اكتشاف المجتمعات
ويمكن أيضا استخدام بنية شبكة لاكتشاف مجموعة من المساهمين في المحتوى، أو ما يسمى مستخدمي المجتمعات، والذين تربطهما مصالح مشتركة؛ يمكن رؤية كل مجتمع على أنها مجموعة من صفحات الويب المترابطة.[15] هناك ثلاثة أسباب رئيسية لاكتشاف المجتمعات:[15]
1. المجتمعات تمتلك في كثير من الأحيان على المعلومات الأكثر قيمة، ذات الصلة، ومحدّثة للمستخدمين المعنيين في تلك المعلومات.
2. المجتمعات تجعل الإنترنت أكثر الاجتماعية، والناس الذين يهتمون في التطور الفكري للويب يستطيعون دراسة تلك المجتمعات.
3. المجتمعات يمكنها أن تخدم الدعايات الموجهة على مستوى دقيق جدا.
مثل هذه
المجتمعات يمكن استخراجها باستخدام خوارزمية هيتس المذكورة سابقا. باختصار،
خوارزمية هيتس تستطيع ايجاد ما يسمى المتجهات
الذاتية الرئيسية، والتي تمثل أكثر المناطق كثافة محتوية على السلطات
والمحاور.[15]
مثال آخر
على مهام تنقيب الويب والتي يمكن أن تكون مفيدة جدا تصنيف صفحات الويب كما هو موضح من قبل تشاكرابارتي وآخرون.[16]
يمكن أن نلاحظ أن تقنيات استخراج البيانات التقليدية لا يمكنها تنفيذ هذه المهام
لأن الجداول العلائقية ليس لها هيكلية الروابط.[2]
3. تنقيب محتوى الويب
نعني بتنقيب محتوى الويب استخدام محتويات صفحات الويب لاستخراج المعلومات المفيدة.[17] تصنيف وتجميع صفحات الويب وفقا لمواضيعهم هي أمثلة على المهام التي تقع ضمن تنقيب محتوى ويب. هذه المهام هي مماثلة لتلك المستخدمة في استخراج البيانات التقليدية.[2] مع ذلك، هناك مهام على شبكة الإنترنت التي لا تعتبر مهام استخراج التقليدية. تشمل الأمثلة استخراج آراء العملاء من مراجعات العملاء ومشاركات الشبكات الاجتماعية، واستخراج مواصفات المنتجات بالإضافة إلى تحليل المشاعر وغيرها الكثير.[2] في الفقرات التالية، سأقوم بمناقشة المهام الرئيسية المستخدمة في تنقيب محتوى الويب بشكل مختصر.
أ. استخراج البينات المهيكلة: توليد المُجمِّع
واحدة من المشاكل الواضحة التي تواجهنا عند استخراج المعلومات هي استخراج بنود المعلومات من صفحات ويب. استخراج المعلومات من نص اللغة الطبيعية يُدرس على نطاق واسع من قبل مجتمعات معالجة اللغة الطبيعية (NLP) البحثية. التحدي من منظور تنقيب ويب هو استخراج البيانات المهيكلة من صفحات الويب.[2]
يسمى
البرنامج الذي يهدف لاستخراج هذه البيانات المُجمِّع.
يتم تمثيل البيانات المهيكلة على شبكة الإنترنت عن طريق إدخال البيانات التي تم
استرجاعها من مصدر البيانات الأساسي المهيكلة، والتي تظهر عادة على صفحات الويب من
خلال جداول وقوالب. على نحو متزايد، العديد من المؤسسات قد تنشر البيانات الخاصة
بهم على مواقع الويب الخاصة بهم، وأصبح من المهم استخراج هذه البيانات لأغراض
كثيرة مثل: جمع المعلومات على الويب للتخصيص، ومقارنة المنتجات، بحث الميتا (meta-search) وغيرها الكثير. هناك
العديد من الأساليب المستخدمة في بناء هذا المُجمِّع. ليو[2] يحدد ثلاثة مناهج:
1. النهج اليدوي: يعتمد هذا النهج كليا على المبرمجين البشريين من خلال مراقبة صفحة ويب وكود المصدر. ثم يستخرج المبرمج القواعد ومن ثم يطور برنامج قائم على هذه القواعد لاستخراج المعلومات المستهدفة. هذا النهج من الواضح غير قابل لاستيعاب صفحات مختلفة أخرى.
2. استقراء المُجمِّع: يعتمد هذا النهج على أساليب التعلم ضمن بيانات معروفة سابقا، حيث يتم تعلم القواعد من صفحات الموصوفة بشكل مسبق أو سجلات البيانات. ثم يتم تطبيق هذه القواعد على صيغ مماثلة لاستخراج عناصر البيانات. مثال على نظام يعتمد على هذا النهج هو النظام ستوكر.[18]
3. الاستخراج التلقائي: هذا النهج يتغلب على جهود وضع العلامات المسبقة يدويا. وهي تعتمد على أساليب التعلم الغير خاضعة للرقابة، والتي يتم استخراج قواعد عناصر البيانات. مثال على هذه التقنية آي إي باد (IEPAD).[19]
ب. تكامل المعلومات
في القسم السابق، ناقشنا بإيجاز كيفية استخراج البيانات على شبكة الإنترنت وتخزينها في مصدر بيانات مهيكل. مع ذلك، جمع البيانات من عدد كبير من المواقع على شبكة الإنترنت يضيف بعدا آخر من التعقيد، ألا وهو تكامل البيانات.[2] من خلال التكامل، فإننا نعني أساسا أمرين:[2]
1. مطابقة الأعمدة في الجداول المختلفة التي تحتوي على نفس النوع من البيانات.
2. مطابقة القيم التي تكون متطابقة دلاليا، ولكن تكون مُمَثّلة بشكل مختلف في أماكن مختلفة.
بشكل
عام، تكامل البيانات تم درسه على نطاق واسع في سياق قواعد البيانات العلائقية
ومستودع البيانات؛ الكثير من بحوث تكامل المعلومات المتعلقة بالويب تعاملت مع
تكامل واجهات استعلام الويب.[2] مع ذلك، العديد من الأفكار التي تم تطويرها بالفعل
يمكن تطبيقها على البيانات المستخرجة من الويب أيضا.[2]
إن المشكلة الرئيسية في تكامل المعلومات تعرف بمطابقة المخطط (schema matching). وتهدف إلى إنتاج مخطط عام
واحد من اثنين أو أكثر من المخططات المختلفة. قبل عملية مطابقة المخطط، وعادة ما
يتطلب خطوات ما قبل المعالجة التي يتعين القيام بها بما في ذلك: التقسيم إلى رموز
صغيرة، والتوسع، وتوحيد الكلمات، وإزالة الكلمات التوقف.[2]
بشكل
أساسي، هناك أنواع مختلفة من المطابقة على النحو الذي اقترحه رام وبيرنشتاين:[20]
1. مطابقة المخطط فقط: يتم
اعتماد معلومات المخطط فقط كالأسماء وانواع البيانات.
2. مطابقة المجال والبيانات فقط: يتم اعتماد البيانات مع معلومات المجال لكل عمود.
3. مطابقة المخطط، والمجال، والبيانات: يتم اعتماد البينات مع معلومات المجال لكل عمود بالإضافة لمعلومات المخطط.
وتوجد عدة طرق لجميع الانواع أعلاه. أما النوع الثاني، وهو مطابقة المجال والبيانات فقط، وهي الحالة الأكثر شيوعا التي تتم في الويب لأنه غالبا يتم إخفاء المخطط.[2] النوع الثالث عادة ما يُمثل مزيجا من التقنيات من النوعين الأولين.[2] مناقشة أكثر تفصيلا لهذه الطرق يمكن العثور عليها في.[20][21]
ت. تنقيب الآراء وتحليل المشاعر
كجزء من الويب يحتوي على البيانات المهيكلة، يحتوي أيضا على كمية هائلة من البيانات غير المهيكلة. هذه البيانات عادة ما تكون نصوص غير مهيكلة. واحدة من مهام التنقيب محتوى الويب الهامة التي تتعامل مع هذه البيانات هو تنقيب الرأي، الذي يجرد المشاعر الإيجابية أو السلبية.[2] وسائل الإعلام الاجتماعي ينمو بسرعة على شبكة الإنترنت بما في ذلك الوظائف شاغرة، المراجعات، المدونات، والمنتديات، ومواقع الشبكات الاجتماعية مثل الفيس بوك وتويتر. هذه المحتويات هي ذات أهمية كبيرة بالنسبة لكثير من الأفراد والمؤسسات وتساعدهم على اتخاذ القرارات.[2] يمكن للأفراد ان تجد العديد من المرجعات على بعض المنتجات على شبكة الإنترنت. المؤسسات عادة تهتم في معرفة آراء عملائهم من المعلومات المتاحة للجمهور على شبكة الإنترنت.[2]
الآراء
يمكن أن تكون عن أي شيء تقريبا بما في ذلك: الخدمات والمنتجات والقضايا
، والموضوعات، والمعدات الإلكترونية، والتطبيقات، وغيرها الكثير. ويسمى الشيء الذي
يتم تقييمه بالكيان. يمكن أن يتكون
هذا الكيان من المكونات والصفات. قد يكون المكون له مكونات فرعية
وصفات، وهكذا.[2] دعونا نلقي نظرة على المراجعة التالية كمثال:
"، ، حصلت على جهاز حاسوب
محمول لينوفو جديد قبل أيام قليلة. إنه حاسوب لطيف. عمر البطارية هو مرضي جدا.
الشاشة نظيفة جدا. جودة الصوت واضحة كذلك، ،"
في المثال أعلاه، الكيان هو حاسوب محمول. أنه
يحتوي على مكونات مثل الشاشة والبطارية. لديه صفات مثل جودة الصوت.
يمكن
تمثيل أي كيان كشجرة من المكونات التي تحتوي على الكيان نفسه كجذر والمكونات
الأخرى كعُقد. كل عُقدة لديها مجموعة من
الصفات. يمكن أن نشكل أي رأي على أي عقدة أو صفة في هذه الشجرة.[2]
مع ذلك،
عادة ما يتم تبسيط هذه الشجرة إلى مستويين باستخدام مصطلح الجوانب والذي يعبر عن كل من المكونات
والصفات. لذلك، الرأي هو في الأساس فكرة سلبية وايجابية، أو محايدة حول كيان أو
جانبا. الصفات بما في ذلك السلبية، والايجابية، والمحايدة تسمى توجهات الرأي. ويطلق على الشخص أو المؤسسة
التي تتبنى رأي صاحب رأي.[2]
لنفرض
الوثائق التي فيها اراء كـ M، الهدف من تنقيب الآراء هو استخراج جميع خماسيات الآراء (ei; aij ; ooijkl; hk; tl) في M، حيث ei هي اسم الكيان، aij هي جانب ei، ooijkl هي توجه الرأي، hk هو صاحب الرأي، tl هو الوقت الذي تم التعبير
فيه عن ذلك الرأي من قبل صاحبه.[2] فبالتالي، استخراج الآراء يتم من خلال تنفيذ المهام التالية:[2]
1. استخراج جميع الكيانات في M وتجميعها في مجاميع، بحيث كل مجموعة تمثل كيان وحيد ei.
2. استخراج منيع الجوانب وتجميعها في مجاميع، بحيث كل مجموعة تمثل جانب وحيد aij.
3. استخراج صاحب الرأي ومعلومة الوقت.
4. القيام بتصنيف جوانب العاطفة لتحديد إن كان الرأي ايجابيا أو سلبيا أو محايدا.
5. وأخيرا، تجميع جميع خماسيات الآراء (ei; aij ; ooijkl; hk; tl) في M كنتيجة من المهام أعلاه.
4. تنقيب استخدام الويب
يشير تنقيب استخدام شبكة الإنترنت لعملية اكتشاف أنماط الاستخدام من البيانات على الويب.[22] يتم تمثيل البيانات الأولية المستخدمة في هذه العملية من خلال سجلات الاستخدام، التي تسجل التفاعلات بين المستخدم وموقع ويب. هذا يتضمن بيانات مثل نقرات المستخدمين، تاريخ ووقت الوصول، عناوين IP، الخ. سجلات الاستخدام عادة ما تكون موجودة على خوادم كما حال سجلات الدخول الملقم وسجلات تطبيق ويب.[22] وعلى غرار عملية استخراج البيانات[10]، غالبا ما تنقسم عملية تنقيب استخدام الإنترنت إلى 3 مراحل، وهي: معالجة مسبقة، اكتشاف الانماط، وتحليل الانماط.[22] صورة 3[2] تُظهر هذه المراحل.
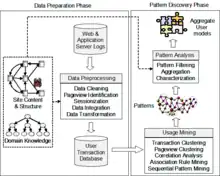
في المرحلة الأولى، مرحلة ما قبل المعالجة، يتم تحويل بيانات الاستخدام إلى تجريدات، والتي تمثل التفاعلات لمستخدم ضمن موقع الويب. يمكن أن تشارك أنواع أخرى من البيانات في هذه المرحلة بما في ذلك بيانات حقيقية في صفحات الموقع، والبيانات التي تصف بنية صفحات الويب، والبيانات التي تمثل معلومات ديموغرافية عن المستخدمين.[22]
في مرحلة
اكتشاف الانماط، يتم تطبيق مجموعة واسعة من الأساليب والتقنيات من مختلف المجالات
مثل الإحصاءات، واستخراج البيانات، وقواعد البيانات، والتعلم الآلي للكشف عن
الانماط المخفية التي تحمل في طياتها سلوكيات المستخدمين.
من
الأمثلة على التقنيات والطرق المستخدمة في هذا النوع من التنقيب كما يلي:[2][22]
1. التحليل الإحصائي: باستخدام الأساليب الإحصائية المختلفة، يمكن أن نجد العديد من المتغيرات التي تهمنا مثل: تصفح الصفحات، وصفحات التي يتم الوصول إليها في أغلب الأحيان، ووقت العرض للصفحات، وأطوال المسارات التنقليّة.
2. قواعد تكوين الروابط: توليد مثل هذه القواعد يمكن أن تستخدم لربط الصفحات أو العناصر التي تم الوصول إليها أو شراؤها بشكل متكرر من قبل المستخدمين. وهكذا، يتم مساعدة مصممي الويب لتنظيم محتوى مواقع الويب الخاصة بهم بكفاءة.
3. التكتل: باستخدام تقنيات التكتل، يمكننا اكتشاف مجموعتين، وهم: مجموعات المستخدمين ومجموعات الصفحات. مجموعات المستخدمين الذين لديهم أنماط التصفح نفسها يمكن أن تكون مفيدة جدا لفرق التسويق، على سبيل المثال، لتزويدهم بمحتويات شخصية.
4. أنماط التسلسل: عن طريق تنقيب أنماط التسلسل، يمكننا معرفة المسارات التنقليّة المتكررة للمستخدمين. كمثال على هذا التنقيب أن يكون شيء من هذا القبيل "على موقع ويب اتش كاريرز، 10% فقط من المستخدمين زار الصفحة الرئيسية، ثم صفحة الوظائف، وأخيرا صفحة العرض".
في
المرحلة الأخيرة، تحليل نمط، الانماط
والإحصاءات التي اكتشفت في المرحلة السابقة يتم تجهيزها لتصفية القواعد أو
الانماط التي لا لزوم لها.[22] يمكن أن تنتج هذه المرحلة النماذج التي يمكن
استخدامها كمدخل لتطبيقات أخرى مثل التصور وأدوات تحليلات الويب ونظم التوصية.[2]
في كثير من الأحيان مطلوب آلية للاستعلام عن المعرفة في هذه المرحلة مثل لغة
الاستعلام الهيكلية (SQL).[22]
5. الخلاصة واتجاهات مستقبلية
مصدر البيانات كالويب، يُعد جديرا جدا للتنقيب واستخراج المعرفة. من ناحية، ثراء وتنوع المعلومات على الويب جعله مصدرا قيما للمعلومات يمكننا من خلاله استخراج الكثير من المعارف المفيدة. من ناحية أخرى، فإنه يجعل عملية التنقيب أكثر صعوبة وأكثر تعقيدا من عملية تنقيب البيانات التقليدية، وخاصة في غياب هيكلية محددة مسبقا.
وقد
دُرست على نطاق واسع العديد من القضايا البحثية في مجال تنقيب الويب. لكن، كما أن
الشبكة ما زالت تنمو في جميع الأبعاد بما في ذلك الهيكل، والمحتوى، ومعلومات الاستخدام[2]،
لا تزال هناك العديد من المجالات، والتي يمكننا أن تستثمر فيها البحوث. يمكن أن
يتم إجراء مزيد من البحوث في توسيع نطاق مقاييس الويب الصحيحة واجراءات الحساب
لهذه المقاييس بحيث يمكن دراسة السلوكيات
المختلفة على شبكة الإنترنت.[23][24] باستخدام البيانات نقر المستخدمين، يمكننا أن
نفعل المزيد من الأبحاث حول تطوير طرق لاستخراج عملية صنع القرار في حد ذاته، وليس
فقط النتائج النهائية لهذه العملية؛ هذا يمكن أن يساعد في تحسين عملية ومعرفة
تأثير مختلف أنحاء عملية ما على مقاييس الويب.[23][24] وقد شوهد أيضا التنقيب في
شبكة الإنترنت كأداة مثالية لكشف ومنع الاحتيال والتهديد. وبالتالي، القضايا
البحثية تشمل التقنيات التي يمكن استخدامها لتطوير طرق لكشف العديد من أنواع
الاحتيال والتهديدات.[23][24] مزيد من التفاصيل حول البحوث والاتجاهات المستقبلية
يمكن العثور عليها في.[23][24]
في هذه
المقالة البحثية، لقد قدمت لمحة عامة عن تنقيب الويب، وأقسامه، وبعض المهام لكل فئة
في تنقيب الويب، وبإيجاز عن المجالات الرئيسية للتوجهات المستقبلية.
انظر أيضًا
- ذكاء الويب
- تحليل الويب
- استخلاص المواقع
- ويكيبيديا:Data mining Wikipedia
المراجع
- د. ج. هاند، ه. مانيلا، وب. سميث، مبادئ تنقيب البيانات، الفصل. المقدمة. صحافة ام أي تي، كامبريدج، 2001. (بالإنجليزية)
- ب. ليو، تنقيب بيانات الويب: استكشاف الروابط التشعبية، المحتويات، و بيانات الاستخدام. شبرينجر للعلوم وادارة الاعمال، 2011. (بالإنجليزية)
- س. م. اتيق، د، انجلي، و ب. ميشرام، "تنقيب الويب والامان في المواقع التجارية الإلكترونية"، في تقدمات في الحوسبة وتقنية المعلومات، ص. 477-487، شبرينجر، 2012. (بالإنجليزية)
- ك. زهاتنج و ر. س. سيجال، "تنقيب البيانات: دراسة حول الابحاث، التقنيات، والبرامج"، المجلة العالمية للتكنولوجيا وصنع القرار، مجلد 7، رقم 04، ص. 683-720، 2008. (بالإنجليزية)
- ك. إيتزيوني، "الشبكة العنكبوتية العالمية: مستنقع أم منجم ذهب؟"، اتصالات أي سي أم، مجلد 39، رقم 11، ص. 65-68، 1996. (بالإنجليزية)
- ز. ماركوف و د. ت. لاروسي، تنقيب بيانات الويب: كشف الغطاء عن الانماط في محتوى الويب، والهيكل، والاستخدام. جون وايلي و ابناءه، 2007. (بالإنجليزية)
- ر. كوسالا و ه. بلوكيل، "بحث تنقيب الويب: دراسة"، استكشافات أي سي ام سيج كيد، مجلد 2، رقم 1، ص. 1-15، 2000. (بالإنجليزية)
- س. ك. مادريا، س. س. بوميك، و. ك. انجي، و ي. ب. ليم، "قضايا بحثية في تنقيب بيانات الويب"، في المؤتمر العالمي الاول لكشف المعرفة ومستودع البيانات، ص. 303-312، شبريتجر، 1999. (بالإنجليزية)
- ج. بروجيس و م. ليفين، "تنقيب البيانات لأنماط المستخدم التنقلية"، في الملف الشخصي للمستخدم وتحليل استخدام الويب، ص. 92-112، شبرينجر. 2000. (بالإنجليزية)
- أ. فياض، ج. باتيسكي شابيرو، و بي. سميث، "من تنقيب البيانات الى استخراج المعرفة في قواعد البيانات"، مجلة الذكاء الاصطناعي . مجلد 17، رقم 3، ص. 1-43، 1996. (بالإنجليزية)
- س. واسرمانو ك. فوست، تحليل الشبكات الاجتماعية: طرق وتطبيقات، مجلد 8، صافحة جامعة كامبريدج، 1994. (بالإنجليزية)
- س. شاكرباتي، ب. دوم، د. جيبسون، ج. كلينبيرج، س. كومار، ب. رافان، س. راجابولان، و ا. تومكينز، "تنقيب هيكل الوصلات للشبكة العنكبوتية"، حاسوب أي تريبل أي، مجلد 32، رقم 8، ص. 60-67، 1999. (بالإنجليزية)
- س. برين ول. بيج، "تشريح محركات البحث التشعبية الضخمة"، شبكات الحاسوب، مجلد 30، رقم 17، ص. 107-117، 1998. (بالإنجليزية)
- ج.م. كلينبيرج، "المصادر الموثوقة في بيئة الارتباط التشعبي"، مجلة أي سي ام، مجلد 46، رقم 5، ص. 604-632، 1999. (بالإنجليزية)
- ر. كومار، ب. رافان، س. راجاجوبلان، و أ. تومكينز، "اصطياد الويب للمجتمعات الإلكترونية الناشئة"، شبكات الحاسوب، مجلد 31، رقم 11، ص. 1481-1493، 1999. (بالإنجليزية)
- س. شاكرباتي، ب. دوم، وب. انديك، "تعزيز تصنيف النص التشعبي باستخدام الارتباطات التشعبية"، سجل أي سي ام سيج مود، مجلد 27، ص. 307-318، أي سي أم، 1998. (بالإنجليزية)
- ف. جونسون وس. ك. جوبتا، "تقنيات التعدين المحتوى على شبكة الإنترنت: دراسة استقصائية"، المجلة العالمية لتطبيقات الحاسوب، مجلد 46، رقم 11، ص. 44، 2012. (بالإنجليزية)
- ي. موسليا، س. مينتون، وك. كنوبلوك، "النهج الهرمي للمّجمِّع التعريفي"، المؤتمر السنوي الثالث حول وكلاء الحكم الذاتي، ص. 190-197، أي سي أم، 1999. (بالإنجليزية)
- س. ه. تشانج وس. س. ليو، "أي أي باد: استخراج المعلومات بناءً على اكتشاف الانماط"، المؤتمر العالم العاشر حول الشبكة العنكبوتية العالمية، ص. 681-688، أي سي أم، 2001. (بالإنجليزية)
- ي. رام وب. ا. بيرنستين، "استطلاع حول المناهج المتبعة لمطابقة المخطط التلقائي"، مجلة في ال دي بي، مجلد 10، رقم 4، ص. 334-350، 2001. (بالإنجليزية)
- ب. شفايكو وج. يوزينات، "استطلاع حول مناهج المطابقة المعتمدة على المخطط"، مجلة دلالات البيانات، ص. 146-171، شبرينجر، 2005. (بالإنجليزية)
- ج. سيرفاستافا، ر. كوولي، م. ديشباندي، وب. ن. تان، "تنقيب استخدام شبكة الإنترنت: اكتشاف وتطبيقات أنماط الاستخدام من البيانات على شبكة الإنترنت"،مجلة استكشافات أي سي ام سيج دي دي، مجلد 1، ؤقم 2، ص. 12-23، 2000. (بالإنجليزية)
- ت. سيرفاستافا، ب. ديسيكان، وف. كومار، "تنقيب الويب - المفاهيم والتطبيقات والاتجاهات البحثية"، التأسيسات والتطور في تنقيب البيانات، ص. 275-307، 2005. (بالإنجليزية)
- ج. د. كوما روم. جوسول، "بحث تنقيب الويب والاتجاهات المستقبلية"، التطور في تطبيقات وأمان الشبكات، ص. 489-496، شبرينجر، 2011. (بالإنجليزية)
Books
- Jesus Mena, "Data Mining Your Website", Digital Press, 1999
- Soumen Chakrabarti, "Mining the Web: Analysis of Hypertext and Semi Structured Data", Morgan Kaufmann, 2002
- Advances in Web Mining and Web Usage Analysis 2005 - revised papers from 7 th workshop on Knowledge Discovery on the Web, Olfa Nasraoui, Osmar Zaiane, Myra Spiliopoulou, Bamshad Mobasher, Philip Yu, Brij Masand, Eds., Springer Lecture Notes in Artificial Intelligence, LNAI 4198, 2006
- Web Mining and Web Usage Analysis 2004 - revised papers from 6 th workshop on Knowledge Discovery on the Web, Bamshad Mobasher, Olfa Nasraoui, Bing Liu, Brij Masand, Eds., Springer Lecture Notes in Artificial Intelligence, 2006
- Mike Thelwall, "Link Analysis: An Information Science Approach", 2004, Academic Press
Bibliographic references
- Cooley, R. Mobasher, B. and Srivastave, J. (1997) “Web Mining: Information and Pattern Discovery on the World Wide Web” In Proceedings of the 9th IEEE International Conference on Tool with Artificial Intelligence
- Cooley, R., Mobasher, B. and Srivastava, J. “Data Preparation for Mining World Wide Web Browsing Patterns”, Journal of Knowledge and Information System, Vol.1, Issue. 1, pp. 5–32, 1999
- Kohavi, R., Mason, L. and Zheng, Z. (2004) “Lessons and Challenges from Mining Retail E-commerce Data” Machine Learning, Vol 57, pp. 83–113
- Lillian Clark, I-Hsien Ting, Chris Kimble, Peter Wright, Daniel Kudenko (2006)"Combining ethnographic and clickstream data to identify user Web browsing strategies" Journal of Information Research, Vol. 11 No. 2, January 2006
- Eirinaki, M., Vazirgiannis, M. (2003) "Web Mining for Web Personalization", ACM Transactions on Internet Technology, Vol.3, No.1, February 2003
- Mobasher, B., Cooley, R. and Srivastava, J. (2000) “Automatic Personalization based on web usage Mining” Communications of the ACM, Vol. 43, No.8, pp. 142–151
- Mobasher, B., Dai, H., Kuo, T. and Nakagawa, M. (2001) “Effective Personalization Based on Association Rule Discover from Web Usage Data” In Proceedings of WIDM 2001, Atlanta, GA, USA, pp. 9–15
- Nasraoui O., Petenes C., "Combining Web Usage Mining and Fuzzy Inference for Website Personalization", in Proc. of WebKDD 2003 – KDD Workshop on Web mining as a Premise to Effective and Intelligent Web Applications, Washington DC, August 2003, p. 37
- Nasraoui O., Frigui H., Joshi A., and Krishnapuram R., “Mining Web Access Logs Using Relational Competitive Fuzzy Clustering,” Proceedings of the Eighth International Fuzzy Systems Association Congress, Hsinchu, Taiwan, August 1999
- Nasraoui O., “World Wide Web Personalization,” Invited chapter in “Encyclopedia of Data Mining and Data Warehousing”, J. Wang, Ed, Idea Group, 2005
- Pierrakos, D., Paliouras, G., Papatheodorou, C., Spyropoulos C. D. (2003) “Web usage mining as a tool for personalization: a survey”, User modelling and user adapted interaction journal, Vol.13, Issue 4, pp. 311–372
- I-Hsien Ting, Chris Kimble, Daniel Kudenko (2005)"A Pattern Restore Method for Restoring Missing Patterns in Server Side Clickstream Data"
- I-Hsien Ting, Chris Kimble, Daniel Kudenko (2006)"UBB Mining: Finding Unexpected Browsing Behaviour in Clickstream Data to improve a Web Site’s Design"
Related Conference
- WMEE 2007: Workshop on Web Mining for E-commerce and E-Services 2007
- WebKDD 2006: SIGKDD Workshop on Web Mining and Web Usage Analysis
- WebMine 2006:Workshop on Web Mining 2006
- WebConMine 2006: Workshop on Web Content Mining 2006
وصلات خارجية
- Web Mining by Patricio Galeas
- Tutorial on Web Mining by Olfa Nasraoui, University of Louisville
- Tutorial on Web Personalization by Olfa Nasraoui, University of Louisville
- Introduction Web Mining by Julio Alberto Herrero, University of Carlos III de Madrid
- TheWebWatcher monitoring service
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تقانة المعلومات
بوابة تقانة المعلومات بوابة إحصاء
بوابة إحصاء