بيانات التدريب والتحقق والاختبار
في تعلم الآلة ، تعد دراسة وبناء الخوارزميات التي يمكن أن تتعلم من البيانات وتصدرها مهمة شائعة. [1] تعمل مثل هذه الخوارزميات عن طريق إجراء تنبؤات أو قرارات تستند إلى البيانات من خلال بناء نموذج رياضي من البيانات المدخلة.[2]
عادةً ما تأتي البيانات المستخدمة لبناء النموذج النهائي من مجموعات بيانات متعددة. على وجه الخصوص ، يتم استخدام ثلاث مجموعات من البيانات بشكل شائع في المراحل المختلفة من إنشاء النموذج.
بيانات التدريب
بيانات التدريب هي مجموعة بيانات من الأمثلة المستخدمة للتعلم ، وهي تناسب المتغيرات (مثل القيم) ، على سبيل المثال ، المصنف.[3][4]
تميل معظم المقاربات التي تبحث من خلال بيانات التدريب عن العلاقات التجريبية إلى مناسبة البيانات ، بمعنى أنه يمكنها تحديد العلاقات الواضحة في بيانات التدريب التي لا تتم بشكل عام.
بيانات التحقق
مجموعة بيانات التحقق عبارة عن مجموعة بيانات من الأمثلة المستخدمة لضبط بنية المتغيرات من المصنف. يسمى أحيانًا مجموعة التطوير . في الشبكات العصبية الاصطناعية ، تكون بنية المتغيرات hyperparameter ، على سبيل المثال ، عدد الوحدات المخفية. يجب أن تتبع مجموعة الاختبار (كما ذكر أعلاه) نفس التوزيع الاحتمالي مثل مجموعة بيانات التدريب.
بيانات الاختبار
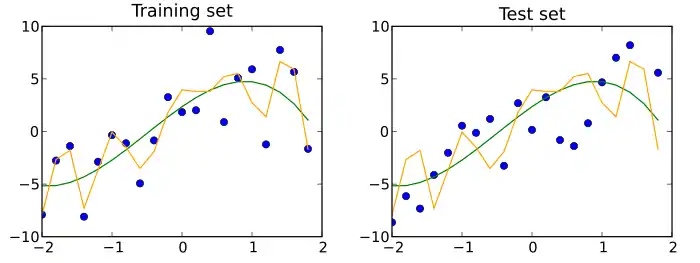
مجموعة بيانات الاختبار هي مجموعة بيانات مستقلة عن مجموعة بيانات التدريب ، ولكنها تتبع نفس توزيع الاحتمالية كمجموعة بيانات تدريبية. إذا كان النموذج المناسب لمجموعة بيانات التدريب مناسبًا أيضًا لمجموعة بيانات الاختبار ، فقد حدث الحد الأدنى من المطابقة الزائدة (انظر الشكل أدناه). عادةً ما يشير التركيب الأفضل لمجموعات البيانات التدريبية بخلاف مجموعة بيانات الاختبار إلى المطابقة الزائد.
وبالتالي ، فإن مجموعة الاختبار هي مجموعة من الأمثلة المستخدمة فقط لتقييم الأداء (أي التعميم) لمصنف محدد بالكامل.
البيانات المعزولة
ببساطة جزء من مجموعة البيانات الأصلية يمكن أن تكون جانبا و تستخدم كمجموعة الاختبار.[5]
المراجع
- Ron Kohavi؛ Foster Provost (1998). "Glossary of terms". تعلم الآلة. ج. 30: 271–274. مؤرشف من الأصل في 2018-07-07.
- Machine learning and pattern recognition "can be viewed as two facets of the same field."
- Ripley, B.D. (1996) Pattern Recognition and Neural Networks, Cambridge: Cambridge University Press, p. 354
- "Subject: What are the population, sample, training set, design set, validation set, and test set?", Neural Network FAQ, part 1 of 7: Introduction (txt), comp.ai.neural-nets, Sarle, W.S., ed. (1997, last modified 2002-05-17) نسخة محفوظة 9 مايو 2020 على موقع واي باك مشين.
- (PDF) https://web.archive.org/web/20180710195839/https://www.researchgate.net/profile/Ron_Kohavi/publication/2352264_A_Study_of_Cross-Validation_and_Bootstrap_for_Accuracy_Estimation_and_Model_Selection/links/02e7e51bcc14c5e91c000000.pdf. مؤرشف من الأصل (PDF) في 2018-07-10.
{{استشهاد ويب}}: الوسيط|title=غير موجود أو فارغ (مساعدة)
 بوابة إحصاء
بوابة إحصاء بوابة برمجة الحاسوب
بوابة برمجة الحاسوب بوابة تربية وتعليم
بوابة تربية وتعليم بوابة تعلم الآلة
بوابة تعلم الآلة